
日本語プロンプト対応の高速画像生成モデルEvoSDXL-JPで生成した画像の例。プロンプトは「可愛いゾウの編みぐるみ」、「ラーメン、浮世絵、葛飾北斎」、「折り紙弁当」、「(下町ロケット、東京サラリーマン)、浮世絵」など
概要
Sakana AIは先日、進化的アルゴリズムを用いた基盤モデル構築の手法「進化的モデルマージ」を提案しました。また、進化的モデルマージにより構築された日本語の大規模言語モデルEvoLLM-JPと画像言語モデルEvoVLM-JPを公開しました。これらのモデルは、言語生成を目的とした自己回帰型Transformerモデルでした。今回私たちは、進化的モデルマージの可能性をさらに示すために、画像生成タスクで広く用いられる拡散モデルへの適用を行いました。
このリリースの要点は以下の通りです。
-
画像生成で昨今用いられている拡散モデルに進化的モデルマージを適用しました。言語生成モデルに限らず、画像生成モデルにおいても進化的モデルマージは効率的にモデルの構築を自動化できました。これは、進化的モデルマージの可能性が幅広いことを示しています。
-
進化的モデルマージによって構築したEvoSDXL-JPは、異なるオープンモデルの融合によって、日本語に対応し日本スタイル画像を生成可能なモデルです。既存の日本語モデルに比べ、推論速度が10倍も高速でありながら、ベンチマークでより良い性能であることを示しています。
-
日本語に対応し高速・低コストな画像生成が可能なEvoSDXL-JPは、生成AIを手軽に試し体験するのに最適なモデルです。より多くの人に生成AIのメリットを享受してもらえるよう、日本の教育現場などでの使用を期待しています。
進化的モデルマージによって構築したEvoSDXL-JPは、研究および教育を目的として、HuggingFaceページにて公開しました。また、すぐに試せるデモを用意しています。ぜひお試しください。
 EvoSDXL-JPを試せるデモを用意しています。是非こちらからお試し下さい。
EvoSDXL-JPを試せるデモを用意しています。是非こちらからお試し下さい。
はじめに
私たちが提案した「進化的モデルマージ」は、自然界の原理を生かした進化的アルゴリズムを基盤とした手法であり、ユーザーが指定した能力に長けた新しい基盤モデルを自動的に作成することができます。また、勾配ベースの訓練を全く必要とせず、比較的少ない計算資源とデータで新しい基盤モデルを自動的に生成できます。詳しくは、リリースブログをご覧ください。基盤モデルの開発に膨大なコストがかかる現在、我々の手法は大きな可能性を秘めていると信じています。
先日のリリースでは、「非英語言語と数学」「非英語言語と画像理解」といった、これまでは困難と思われていた全く異なる領域のモデルの融合(マージ)を、我々の手法で自動的に行い、高い性能の基盤モデルの構築に成功したことを示しました。実験的に構築したモデルとして、日本語の大規模言語モデル(LLM)と数学のLLMをマージすることでできたEvoLLM-JPは、数学のみならず、日本語の全般的な能力に長けていることが分かりました。また、日本語LLMと画像言語モデル(VLM)をマージしてできたEvoVLM-JPは、日本文化の知識にも対応でき、日本の画像と日本語のテキストを利用したベンチマークでも最高の結果を達成しました。
EvoLLM-JPやEvoVLM-JPは、進化的モデルマージを、言語生成で用いられる自己回帰型Transformerモデルへ適用したモデルでした。進化的モデルマージは、言語生成というタスクや自己回帰型Transformerというモデルに限らず、原理的にはあらゆるタスク、モデル構造に対応することが可能です。その1つの例として、私たちは、進化的モデルマージを、画像生成タスクにおける拡散モデルへ適用し、高性能な画像生成モデルの構築が可能であることを示します。

プロンプト:「ラーメン、浮世絵、葛飾北斎。」
日本語画像生成モデル(EvoSDXL-JP)
昨今の画像生成モデルは、拡散モデルを基盤としており、高性能な画像生成が可能になっています。特に、SDXL、DALLE-3をはじめとしたtext-to-imageモデルは、テキストプロンプトに沿った高性能な画像が生成され、多くの反響を呼んでいます。しかし、拡散モデルを基盤とした画像生成モデルは、推論速度が遅いという課題があります。これは、拡散モデルがノイズ画像から徐々にノイズを除去するステップを繰り返すことで画像を生成するという仕組みに起因します。この課題に対して昨今多くの研究が行われ、最近では一般的な拡散モデルに比べ、およそ1/10程度のステップ数で画像を生成できるようにする手法が提案されています。画像生成の処理時間はステップ数に比例するため、これらの手法は一般的な拡散モデルに対しおよそ10倍の速度で画像が生成できます。
また、多くの公開されている画像生成モデルは、英語プロンプトのみに対応しています。そのため、非英語話者のユーザーは「呪文」としてテキストプロンプトを調整し、画像生成を試みているのが現状です。また、機械翻訳を用いて日本語から英語に直す場合、コストが高く、翻訳機の性能に依存し、日本特有の表現の使用が限定されます。現在、公開されている日本特化の画像生成モデルは、日本語プロンプトに対応し日本スタイルの画像生成が可能ですが、従来の拡散モデルと同様に推論速度に課題があります。そこで私たちは、進化的モデルマージにより日本特化の高速な画像生成が可能なモデルを構築しました。
構築には、進化的モデルマージを2段階で適用しました。まず、日本特化の画像生成モデルと英語の基盤画像生成モデルをマージし、日本語対応した高性能な画像生成モデルを構築しました(以下の表のモデル6に対応)。そして、できたモデルをさらに高速画像生成モデルとマージすることで、日本語対応かつ高速な画像生成モデルであるEvoSDXL-JPを構築しました(以下の表のモデル7に対応)。。一度、高性能な英語の基盤モデルとマージすることで、さらなる高性能化を実現しました。
以下に評価結果を示します。性能の評価指標には、生成された画像と真の画像の近さを表すFID(小さい値ほど良い)と人間好みの度合いを測るHPS(Human Preference Score)(大きい値ほど良い)を利用しました。FIDはCOCOデータセットに対する日本語キャプションSTAIR-captionsの検証データ1万件に対して計算し、HPSは元のベンチマークを翻訳した日本語キャプションを用いて生成された画像に対して計算を行いました。なお、これは進化的アルゴリズムによる最適化に用いた学習セットとは異なります。
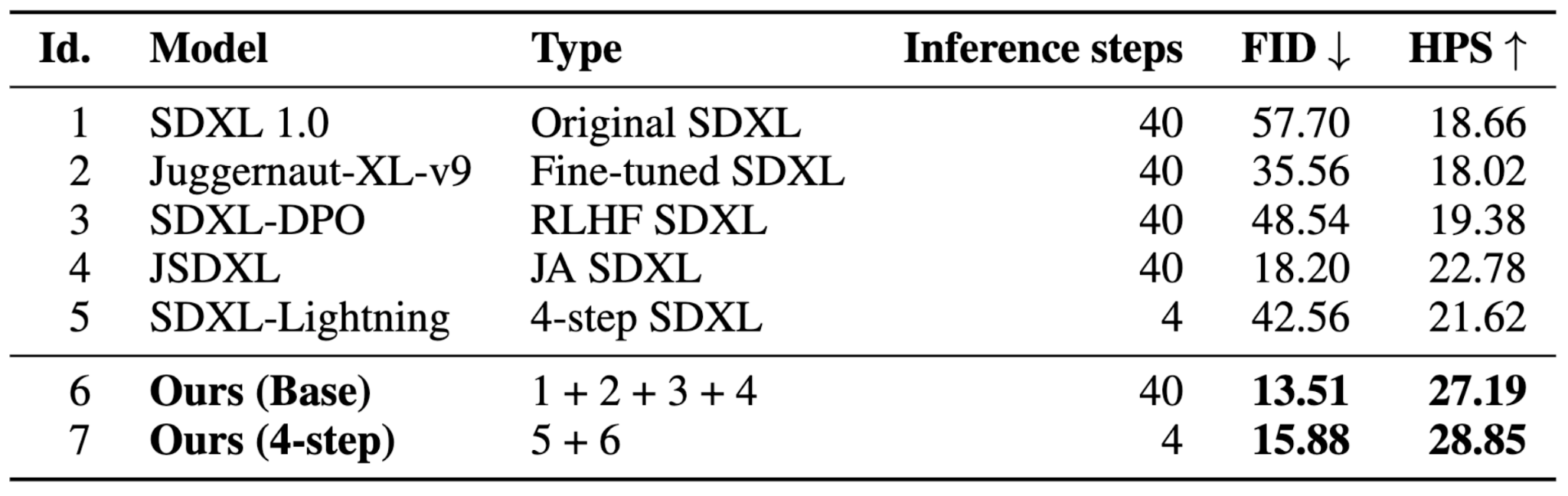
我々が構築したEvoSDXL-JP(モデル7)は、従来の推論に40ステップを要する日本語モデルに比べ、わずか4ステップと推論速度が10倍であり、高速な画像生成が可能です。さらに、FIDは、既存モデルと比べ最高性能であり、日本語プロンプトを忠実に理解した画像が生成できることを示しています。また、HPSにおいても、最高スコアを達成しており、より人間好みな画像生成が可能であることを示しています。
次に、実際の生成例を見ていきます。日本語を理解し、複雑なテキストを入力せずとも、テキストに沿った高精度な画像生成が可能です

「波に乗っている1個のりんご」、「雲を泳ぐ魚のポートレート」と入力した生成結果

「折り紙味噌汁」、「折り紙弁当」と入力した生成結果

「可愛い一匹の魚、編みぐるみ」、「可愛いうさぎ忍者、編みぐるみ」と入力した生成結果

「お笑い芸人、編みぐるみ」、「お相撲さん、編みぐるみ」と入力した生成結果
EvoSDXL-JPは、日本語対応した高速な画像生成が可能な生成AIです。そのため、理想の画像に近づけるためのテキストプロンプトの試行錯誤も、より簡単に行うことができます。生成AIが注目されている今日、AIを自身のエッジデバイスへインストールし気軽に試し体験することは、生成AIを知るきっかけの1つとなり、より多くの人に生成AIのメリットを享受してもらえると考えております。EvoSDXL-JPは、そのような教育目的の使用に適したモデルです。ぜひお試しください。
今後の展望
このリリースでは、進化的モデルマージのさらなる可能性を示すため、画像生成タスクにおける拡散モデルへの適用を紹介しました。特に、日本にルーツを持つAIラボとして、日本向けの画像生成モデルの構築に取り組みました。今回の成果が示したように、進化的モデルマージは、特定のモダリティに限定されず、原理的にあらゆるモダリティのモデルへ適用することができます。今後のAI開発において、進化的アプローチにより既存のモデルを組み合わせることで、低コストで様々なモダリティのモデルを構築する傾向が強まっていくと考えております。私たちは、モダリティを限定せず、根本的な課題解決に今後も尽力してまいります。
Sakana AI
進化的計算と基盤モデルの更なる発展を自ら切り開きたい方は、当社の募集要項をご覧ください。

プロンプト:「(ロボット魚、東京タワー、味噌ラーメン、スマートフォン)、最高品質の浮世絵、江戸時代。」