
Summary
At Sakana AI, we harness nature-inspired ideas such as evolutionary optimization to develop cutting-edge foundation models. The development of deep learning has historically relied on extensive trial-and-error by AI researchers and their theoretical insights. This is especially true for preference optimization algorithms, which are crucial for aligning Large Language Models (LLMs) with human preferences. Meanwhile, LLMs themselves have grown increasingly capable of generating hypotheses and writing code. This raises an intriguing question: can we leverage AI to automate the process of AI research and discovery?
Earlier this year, Sakana AI started leveraging evolutionary algorithms to develop better ways to train foundation models like LLMs. In a recent paper, we have also used LLMs to act as better evolutionary algorithms!
Given these surprising results, we began to ask ourselves: Can we also use LLMs to come up with a much better algorithm to train LLMs themselves? We playfully term this self-referential improvement process LLM² (‘LLM-squared’) as an homage to previous fundamental work in meta-learning.
As a significant step towards this goal, we’re excited to release our report, Discovering Preference Optimization Algorithms with and for Large Language Models.
In this release:
-
We propose and run an LLM-driven discovery process to synthesize novel preference optimization algorithms.
-
We use this pipeline to discover multiple high-performing preference optimization losses. One such loss, which we call Discovered Preference Optimization (DiscoPOP), achieves state-of-the-art performance across multiple held-out evaluation tasks, outperforming Direct Preference Optimization (DPO) and other existing methods.
-
We provide an initial analysis of DiscoPOP, to discover surprising and counterintuitive features.
We open-source not only the tuned model checkpoints and discovered objective functions but also the codebase for running the discovery process itself on GitHub and HuggingFace. Furthermore, we are honored to have collaborated for this project with the University of Oxford and Cambridge University.
As researchers, we are thrilled by the potential of our method to discover new optimization algorithms with minimal human intervention. This not only reduces the need for extensive computational resources but also opens new avenues for exploring the vast search space of optimal loss functions, ultimately enhancing the capabilities of LLMs in various applications. Ultimately, we envision a self-referential process in which advancements in AI research feedback into faster and more efficient discovery of scientific advancements.
In this work, an LLM is prompted to propose and implement new preference optimization loss functions based on previously-evaluated performance metrics. This process leads to the discovery of previously-unknown preference optimization algorithms. The best performing of these we call Discovered Preference Optimization (DiscoPOP), a new state-of-the-art algorithm for training LLMs to align with human preferences.
Introduction
The quest to enhance artificial intelligence (AI) is a journey marked by continuous discovery and innovation. This enormous potential has already diffused into various subfields of science including recent advances in automated drug discovery, mathematical theorem solving or improving core operations in computer science.
Historically, the development of AI models themselves has been driven by human ingenuity and countless hours of experimentation. This process, while fruitful, is inherently limited by the scope of human creativity and the extensive resources required.
At Sakana AI, on the other hand, we are pioneering a new approach to AI development by combining the power of Large Language Models (LLMs) with approaches inspired by biological evolution. As LLMs become more proficient in generating hypotheses and writing code, a fascinating possibility emerges: using AI to advance AI itself. This approach aims to transcend the traditional boundaries of human-driven research, opening new avenues for innovation. Furthermore, it paints a path for amortizing the enormous costs of training foundation models, e.g. by feeding improvements in reasoning capabilities directly back into the process of next-generation model development.
As a first case study we chose the field of preference optimization as a prime candidate for this transformative approach. Preference optimization algorithms are crucial for aligning LLM outputs with human values, ensuring that AI systems generate useful, ethical, and relevant responses. In our latest report, Discovering Preference Optimization Algorithms with and for Large Language Models, we present a significant step towards automating the discovery of such application crucial approaches. More specifically, we use LLMs to propose and refine new preference optimization algorithms. This method not only accelerates the discovery of effective algorithms but also reduces the reliance on extensive human intervention and computational resources.
An Evolutionary Approach to Discovering Objective Functions
There is a growing field that aims to leverage foundation models for black-box optimization. Notably, this includes the use of LLMs to design reward functions for Reinforcement Learning, improve Data Science workflows or even entire virtual environments exploiting human notions of interest.
Here, more specifically, we take an evolutionary LLM perspective and use them as code-level mutation operators:
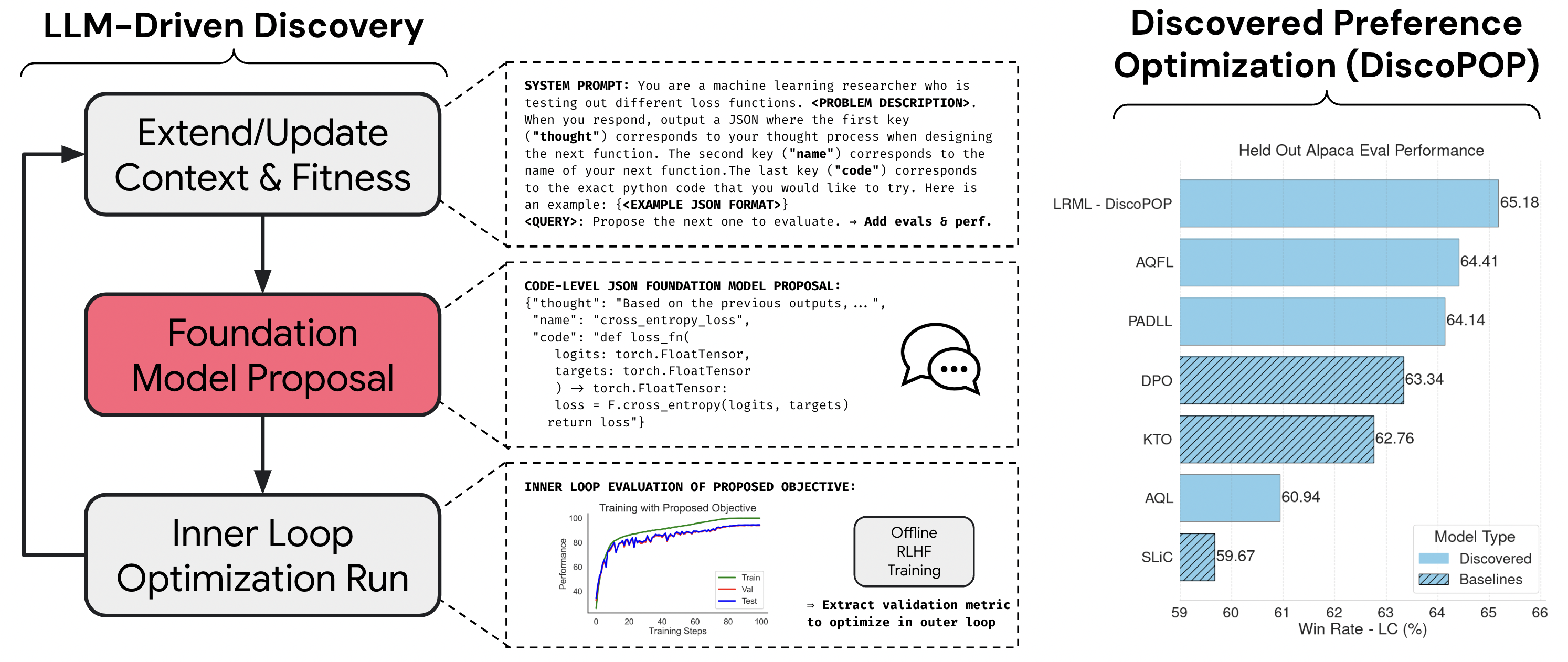
Our general LLM-driven discovery approach can be grouped into three steps:
-
First, we prompt an LLM with an initial task and problem description. We optionally add examples or previous evaluations and their recorded performance to the initial prompt.
-
The LLM is tasked with outputting a hypothesis, a name for the new method, and a code implementation of their method. We use the code in an inner loop training run and store the downstream performance of interest.
-
Finally, we update the context of the LLM with the results from the newly evaluated performance.
Note that this process is in principle much more generally applicable and we are only considering the case of objective function discovery. It could for example also be used to design new model architecture components or even optimization algorithms.
Interestingly, throughout our experiments we observe that the LLM-driven discovery alternates between several different exploration, fine- tuning, and knowledge composition steps: E.g. for a classification task the LLM initially proposes a label-smoothed cross-entropy objective. After tuning the smoothing temperature, it explores a squared error loss variant, which improved the observed validation performance. Next, the two conceptually different objectives are combined, leading to another significant performance improvement. Hence, the LLM discovery process does not perform a random search over objectives previously outlined in the literature but instead composes various concepts in a complementary fashion. Furthermore, the LLMs “thought” output clearly indicates an intelligent thought and composition process. While the “name” summarizes the proposed concepts in a surprisingly accurate manner.
Discovering State-of-the-Art Preference Optimization Methods
Offline Preference Optimization is used to align language models to human feedback. Over the past year, several methods have been proposed–however, they often only differ in their objective functions by a few lines of code! Thus, we can use the above approach to discover new preference optimization algorithms.
We include an example of a single generation below, where the model first outputs a “thought”, then it names the function and provides its implementation in code:

We run this search for around 100 generations and catalog the best performing ones below. We use mathematical notation for brevity:

We found many objective functions (named and created by an LLM!) that outperform human-designed ones! To make sure we don’t overfit to MT-Bench, we then evaluate these objective functions on held-out tasks, such as AlpacaEval 2.0, and show the results below:
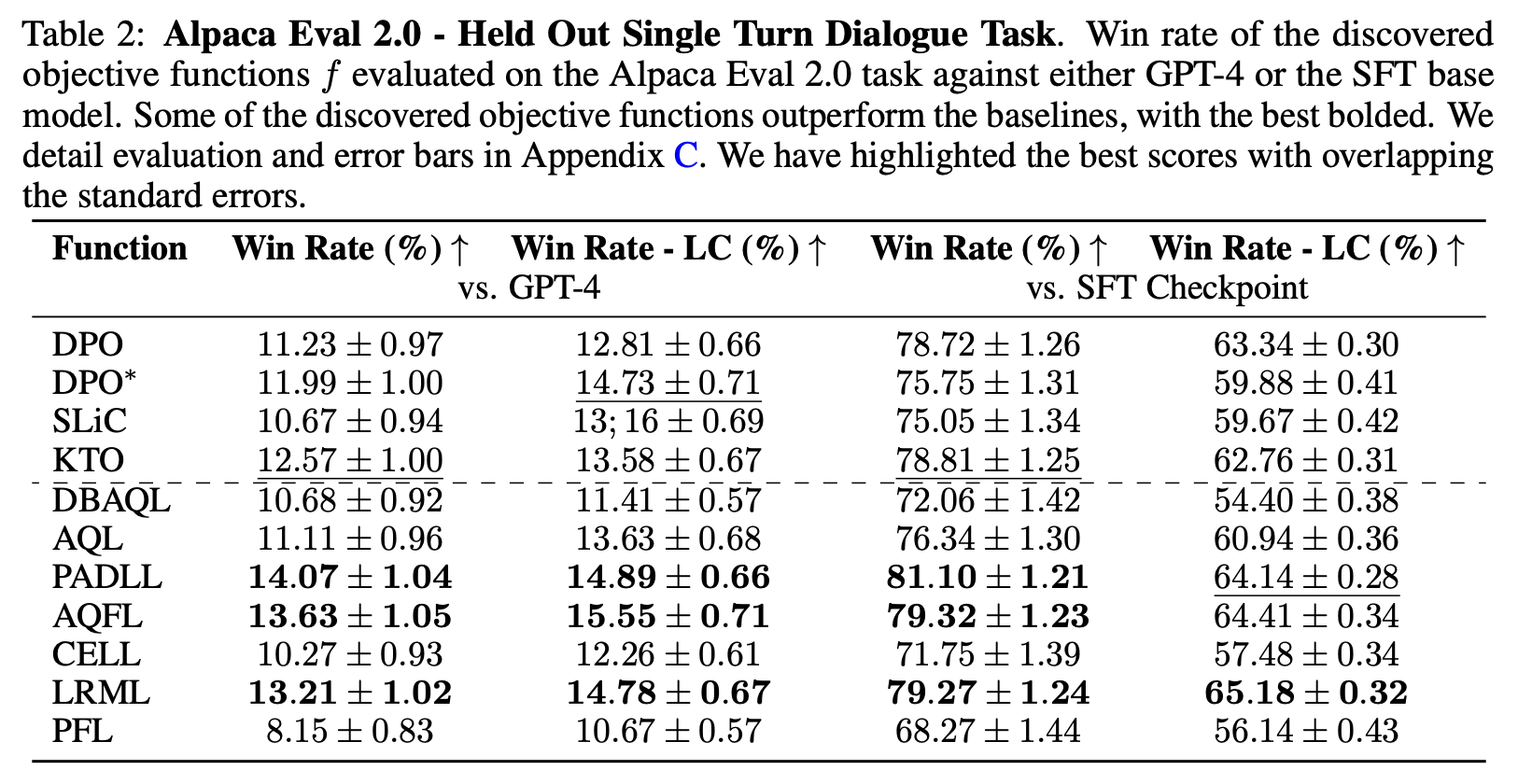
The results generally hold up! In particular, across numerous benchmarks, datasets, and base models, we find that the “LRML” loss performs well. Because of this, we refer to this objective function as Discovered Preference OPtimization (DiscoPOP). We show the code (and comments) that the LLM generated for DiscoPOP below:

This loss function has several interesting features. For one, it’s not convex! Notably, we find that when evaluating DiscoPOP on other tasks and across various hyperparameters, there are many nice properties. For instance, DiscoPOP achieves a higher score (Reward) while deviating less from the base model (KL Divergence).
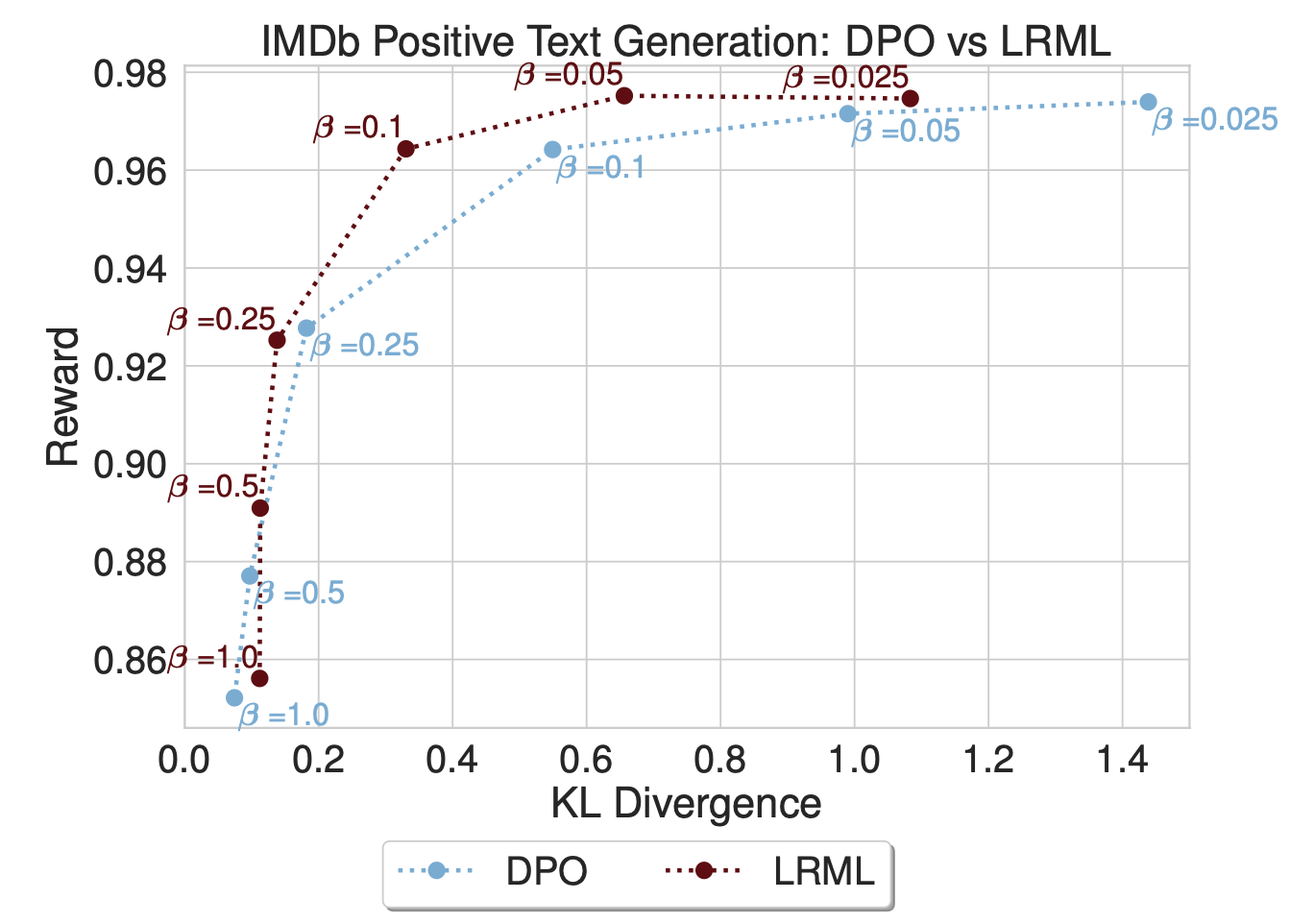
DiscoPOP achieves a higher score (Reward) while deviating less from the base model (KL Divergence), compared to existing state-of-the-art methods such as DPO. We perform a deeper analysis of this loss function in our report.
The Future: A Fully Automated AI Researcher that Open-endedly Improves Itself (LLM²)

A fully automated AI fish that open-endedly improves itself.
There are many exciting paths forward to further push the proposed automated discovery process. These include the usage of more information gathered during each generation by for example using a Visual Language Model with training curve plots. Furthermore, the prompt-structure itself can be meta-learned or modulated by another LLM. Finally, we think that better methods for sampling candidate solutions are necessary. This could for example be achieved via leveraging multiple proposal LLMs or smarter decoding techniques.
Our work highlights the enormous potential of leveraging modern AI to generate self-improvement processes. In the future, we envision that this approach could be run in an open-ended fashion. I.e., an LLM repeatedly proposes to modify parts of itself (training or inference stack) or parts of different agents, which ultimately feedback into itself (e.g. via debate).
In this project, we studied the code-proposal capabilities of various different LLMs including GPT-4, Gemini-1.5 and Llama-3. While all of the models were in general capable of generating suitable objective functions, in the end we decided to use a frontier model, GPT-4, to assess what is currently feasible. We expect the capabilities discovered in this work to be possible with most other frontier models, including open-source models. In fact, we are currently running more experiments using open-source LLMs and are getting promising results! In the future, we would like to use the proposed discovery process to produce self-improving AI research in a closed-loop and using open models.
Sakana AI
Want to take evolutionary computing for automated LLM development to the next level?
Please see our Careers page for more information.