
This is the first in a series of blog posts presenting the results of Sakana AI’s research projects that were supported by the Japanese Ministry of Economy, Trade and Industry’s GENIAC supercomputing grant.
Summary
In evolutionary biology, an ecological niche refers to the relationship a species has with its environment determined by its unique abilities and characteristics. A specie’s niche encompasses the set of things that enables it to survive. These include specific skills and abilities that determine the prey it eats, the living space it occupies, etc. Generally, once occupied, a niche is typically highly resilient to invasion, making it challenging for other species to displace the incumbent species.
The concept of an ecological niche can also be applied to AI agents. An AI agent’s niche is defined by its capabilities, the tasks it can perform, and the resources it consumes. A well-evolved agent can effectively occupy a specific niche, making it resilient to competition from other agents. This approach can enable a population of AI agents to emerge, each with specific capabilities that complement each other, collectively improving over time.
We explore this concept in our recent paper, Agent Skill Acquisition for Large Language Models via CycleQD, where we propose a framework called CycleQD for evolving a swarm of LLM agents, each with their own niche, to tackle difficult agentic workflow tasks.
Unlike existing post-training pipelines for fine-tuning LLMs, our method is based on an evolutionary process, using techniques such as model merging (which we have previously explored) as an evolutionary operation. Our approach is able to produce a population of relatively small LLM agents, each with only 8B parameters, that are highly capable in various challenging agentic benchmarks, particularly in computer science tasks. Furthermore, our approach extends to other non-language domains, such as image segmentation.
The current paradigm of developing ever-larger foundation models leads to ever-larger computationally demanding resource requirements. We believe rather than aiming to develop a single large model to perform well on all tasks, population-based approaches to evolve a diverse swarm of niche models may offer an alternative, more sustainable path to scaling up the development of AI agents with advanced capabilities.
The core idea in CycleQD is in our use of Model Merging as an evolutionary cross-over operation, and SVD as a mutation operation, with a Quality Diversity-based selection operation. Starting with task-specific experts in the initial population, CycleQD evolves a diverse population of small models that excel in agentic tasks while preserving general language capabilities.
What is Quality Diversity?
Imagine you are exploring a wizard world, collecting magical beans. Instead of obsessing over finding the best bean, you want a whole collection of them with different colors, shapes and flavors. This is the heart of Quality Diversity (QD), a recent paradigm of evolutionary computing, which focuses on discovering a variety of solutions, each excellent in its own unique way.
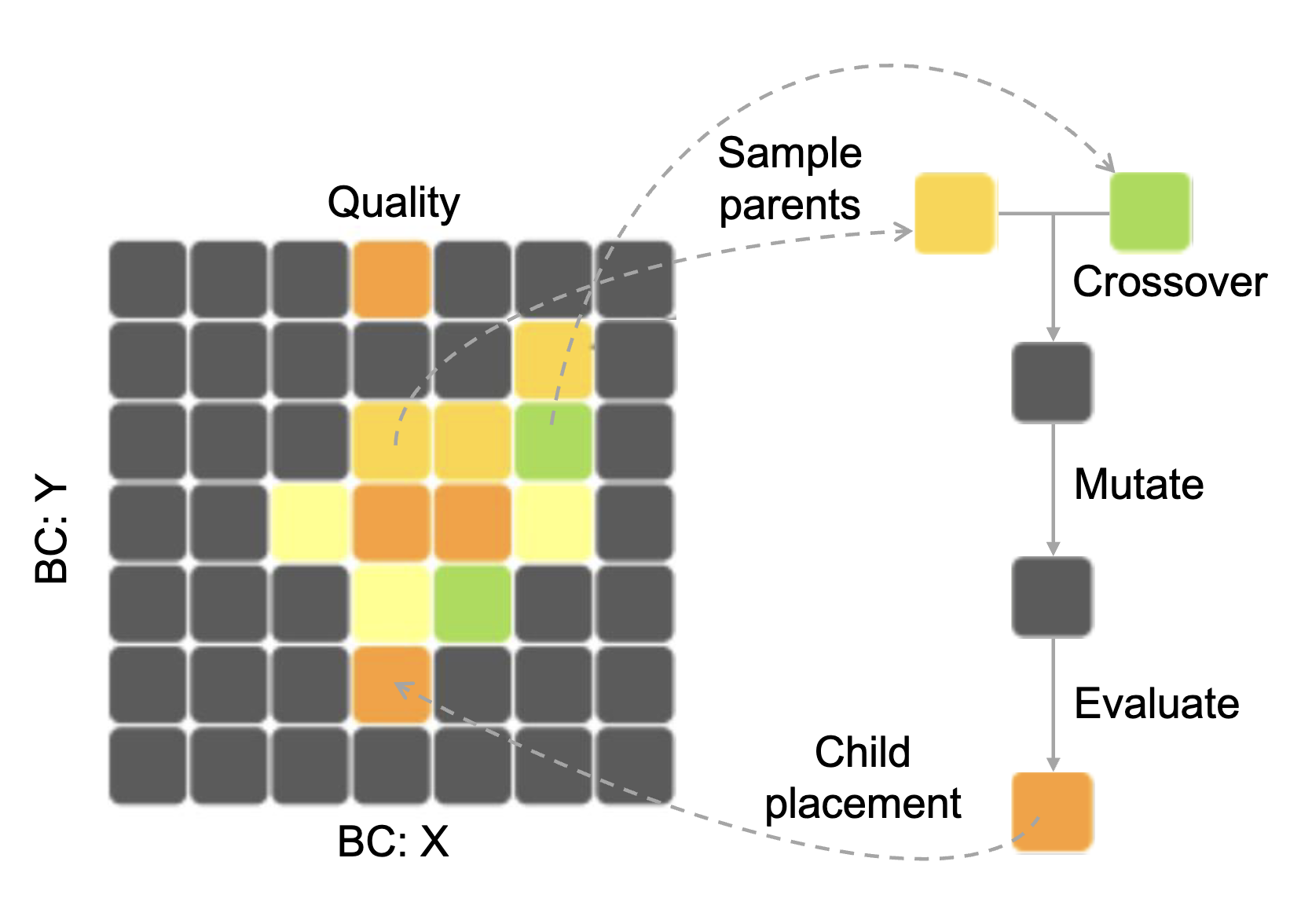
Now, think of the grid in the figure above as your bean collection chest. Each square represents a unique kind of feature of the beans, like their color and magical effect. In QD’s language, these features are called Behavior Characteristics (BCs), and as we will see shortly, they can also be viewed as skill domains. Your goal is to fill this chest with a preferable bean for each square, ensuring your collection is both diverse and top-notch. Here, “preferable” is measured by a user-defined metric (e.g., bean size), which QD calls Quality.
But how do we collect more diverse beans? This is where evolutionary algorithms (EA) come into play. Since we are in a wizarding world, imagine these beans can give birth to babies. We can pick two “parent” beans from the chest, and through a little wizardry, known as crossover and mutation in EA’s language, a new bean is born. The “baby” bean is then evaluated to see how colorful and magical it is, and which square in your chest it belongs to. If the resulting bean is of higher quality than the bean already in that square (e.g., bigger), the new bean replaces it as the new champion. Repeat this magic process over and over, and watch the chest fill up by “magic” (i.e. EA).
Introducing CycleQD
Quality Diversity isn’t just for collecting magical beans, it has powerful implications and applications in real-world problems too, and can help provide new perspectives on how we approach certain problems. In education, we cultivate diverse talents in STEM, sports, and the humanities to build a well-rounded society. In startups, teams thrive when talents are complementary and diverse. Inspired by these principles, in our paper, we show how QD can be incorporated into the post-training pipeline of LLMs to help them learn new, complex skills like coding, or performing database and operating system operations.
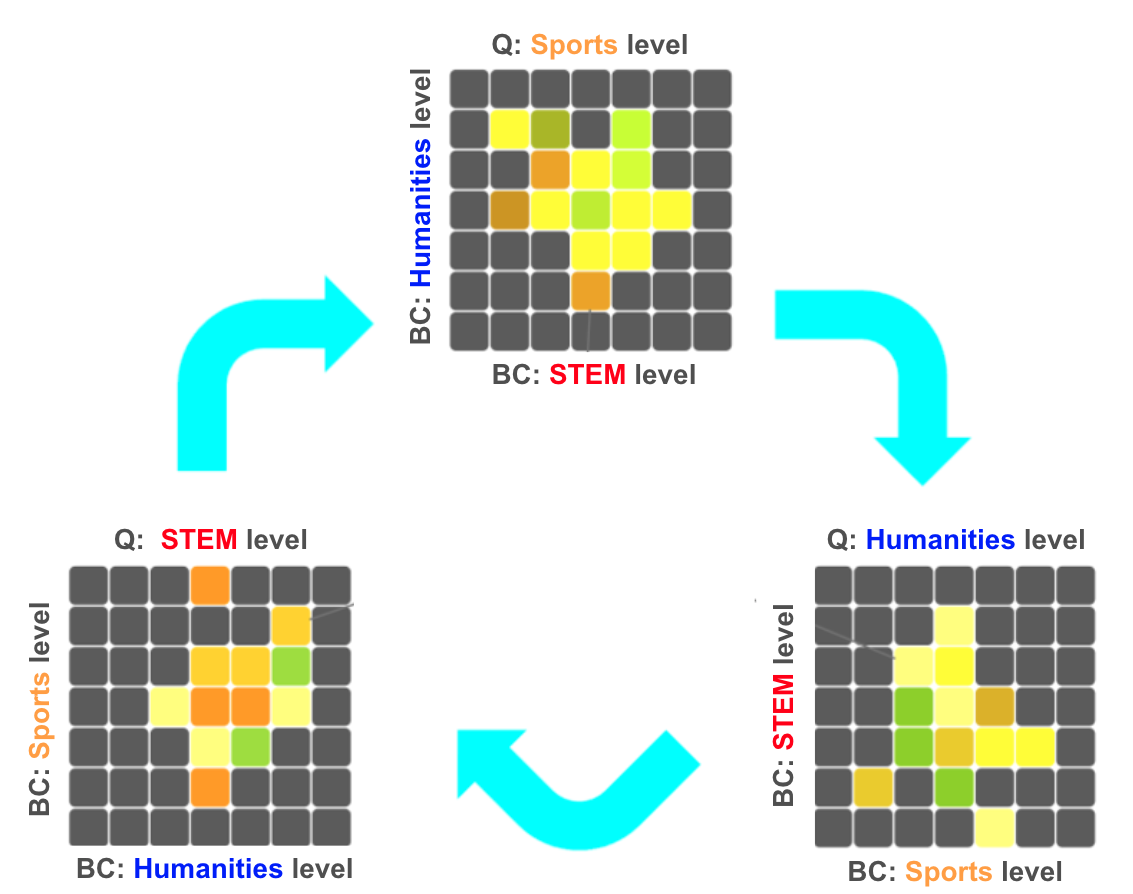
Observing the “Quality Diversity” of a group of students under our CycleQD framework. For example, in the top perspective in this figure, the x-axis is performance in STEM, the y-axis is performance in Humanities, while the color is indicative of the student’s performance in Sports. We can “cycle” the perspectives to view the STEM or Humanities performance with respect to the other domains.
Training LLMs to master multiple skills comes with two major challenges:
- Balancing data from different tasks so none are over- or under-represented.
- Optimizing for multiple skills at the same time without one skill dominating the others.
To tackle these issues, we developed a new method called CycleQD.
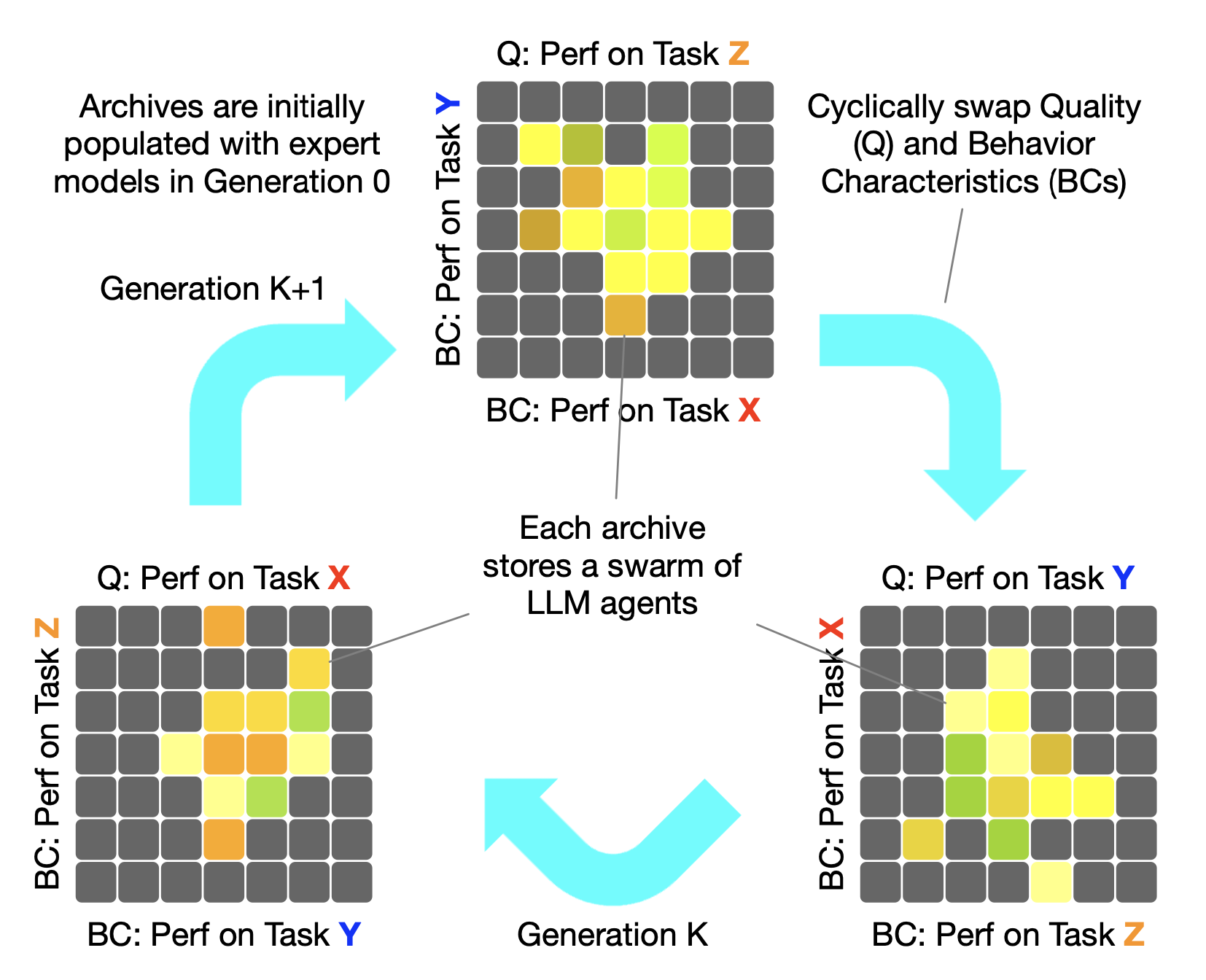
Cyclically Alternating Quality and BCs
Imagine our beans collection chest has transformed into a high-tech LLMs collection chest. This chest is no longer limited to two dimensions but extends into K dimensions, where K is the number of skills we want the LLMs to learn. Each dimension measures the LLM’s performance on one skill (e.g., coding or database operations). These skill performances are our BCs, which now measure how well each individual performs across different domains. In an educational metaphor, a student in a CycleQD chest grid might have scores (A, A+, B+) on (Math, Sports, Literature).
Just like with the beans, we still use crossover and mutation to create new models. But here’s the twist: instead of sticking to one preference (like bean size), we cycle through the skills. For each new LLM we generate, we pick one skill’s performance as the Quality to optimize, while using the other skills as BCs. In the context of education, this is like focusing on improving Math → Sports → Literature → (back to) Math in a cyclic fashion. This ensures every skill gets its moment in the spotlight, allowing the LLMs to grow more balanced and capable overall. See the figure above for a visual explanation.
Model Merging-based Crossover and SVD-based Mutation
In CycleQD, we first prepare specialized expert LLMs for each of the K skills, and by repeatedly applying crossover and mutation based on these models, we add high-quality models to the collection box.
Model Merging-based Crossover: Instead of combining beans, we now merge LLM models. We start with a collection of expert LLMs, each specialized in one of the K skills. During crossover, we select two models from the box and merge them to create a new LLM with combined abilities. This technique, which we have developed in earlier research, is cost-effective and produces well-rounded models quickly.
SVD-based Mutation: Instead of making random adjustments to the model, we use a technique called Singular Value Decomposition (SVD). Think of it as breaking a model’s skills into their fundamental components or sub-skills, like breaking down math into reasoning and computation. By tweaking these key components, we give the new model the chance to explore fresh possibilities beyond what its “parents” could do. This approach not only helps the model avoid getting stuck in predictable patterns but also makes it less likely to overfit, leading to better overall performance.
Main Results
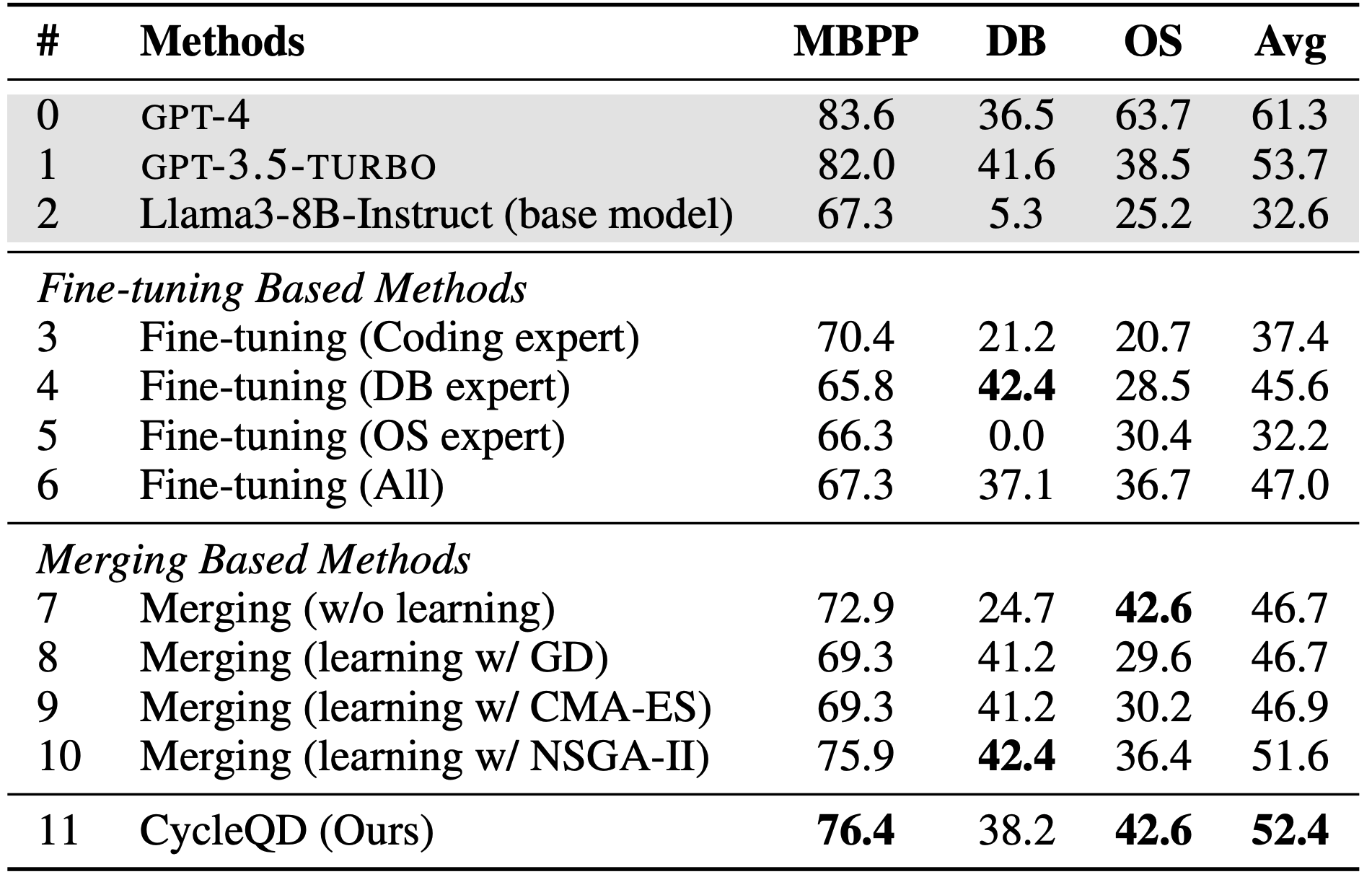
In one of our experiments, we applied CycleQD to train Llama3-8B-Instruct on three computer science tasks: Coding (MBPP), Database (DB) and Operating System (OS) operations. CycleQD demonstrated superior performance across multiple tasks, outperforming traditional fine-tuning and model merging approaches. We show the main results in the table below.
Note that the coding task is abbreviated as MBPP, as we have used the popular Mostly Basic Python Programming benchmark.
Evaluation on computer science tasks. We report pass@1 for MBPP and success rates for the DB and OS tasks. The base model and the GPT models (in gray) are included for completeness. Except for the GPT models, all the models contain 8B parameters.
The following figure visualizes CycleQD’s results at the end of the experiment, projected into two dimensions for visualization purposes. Each perspective highlights two BCs on the axes, while the color intensity in the grids represents the models’ Quality.
For example, in the middle perspective in the figure below, the x-axis is performance on Coding (MBPP), the y-axis is performance on Operation System (OS), while the color is indicative of the models’ performance on Database (DB).
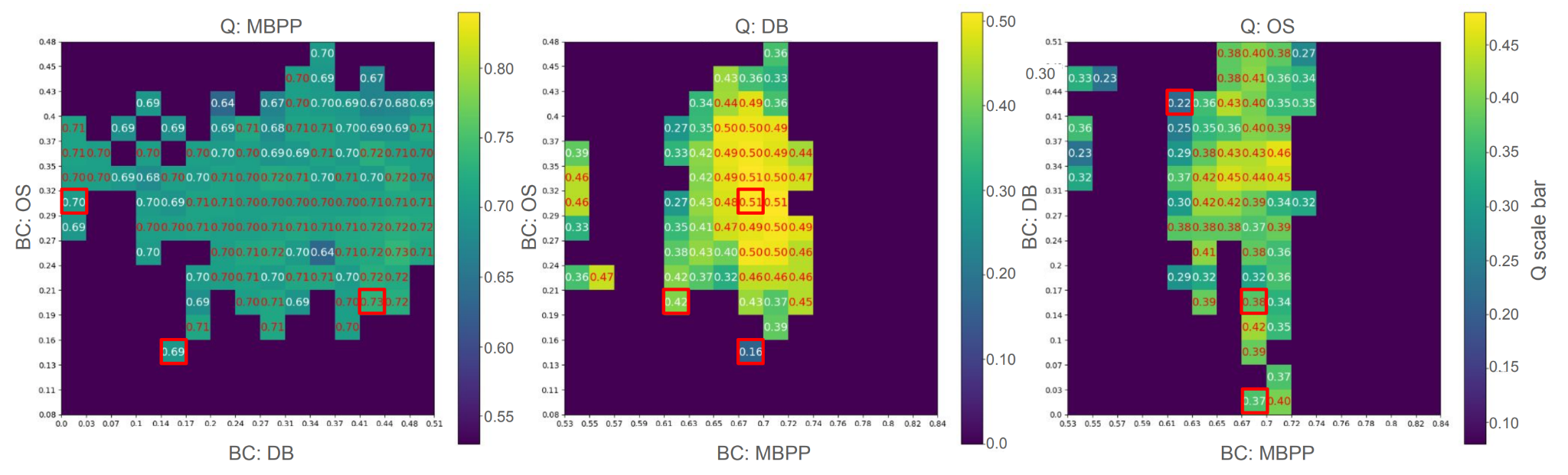
The red bounding boxes mark the starting points of the three initial expert models. As you can see, the chest isn’t just populated with models specialized in a single skill, it is now filled with diverse models, many of which are capable across multiple tasks. This visualization demonstrates how CycleQD effectively builds a rich and varied collection of models, covering a wide range of skills and abilities.
These results clearly show that CycleQD outperforms traditional methods, proving its effectiveness in training LLMs to excel across multiple skills. If you are curious to see how CycleQD stacks up against approaches like fine-tuning and our previous model merging, or if you would like a deeper dive into the results, be sure to check out our full paper for further details.
The Future: Life-long Learning and Swarm of Agents
The future of AI lies in life-long learning wherein systems continuously grow, adapt, and accumulate knowledge over time. CycleQD represents a step toward this vision, enabling diverse skill acquisition as a foundation for continual learning.
Another exciting direction is multi-agent systems. With CycleQD generating a collection of diverse agents, the potential to orchestrate these agents to collaborate, compete, and learn from one another opens up new possibilities. From scientific discovery to real-world problem-solving, swarms of specialized agents could redefine the limits of AI.
Acknowledgement
We extend our heartfelt gratitude to the New Energy and Industrial Technology Development Organization (NEDO) and the Japanese Ministry of Economy, Trade and Industry (METI) for organizing the Generative AI Accelerator Challenge (GENIAC) and for selecting us as one of the participants. This project, JPNP20017, was made possible through the support provided by this initiative.
Sakana AI
Interested in joining us? Please see our career opportunities for more information.