Sakana AIはLLMエージェントの集団を生み出す新技術「CycleQD」を開発しました。CycleQDは多様性に着目した進化的計算とモデルマージに基づいており、知識やスキルを忘却せず蓄積していく「生涯学習」の実現への第一歩です。
本稿は、経済産業省のGENIACによって支援されたSakana AIの研究成果を紹介するブログシリーズの第1回目です。
概要
生物界において「ニッチ(生態的地位)」各生物種が持つ独自の能力や特性によって決定される環境との関係性を指します。これには獲物の捕食方法や生息環境の選択など、生存に必要な様々な要素が含まれます。一度確立されたニッチは、他種からの侵入に対して高い耐性を持ち、その地位を脅かすことは容易ではありません。
この概念はAI分野にも応用可能です。AIエージェントの「ニッチ」は、そのエージェントが持つ能力や、実行可能なタスク、必要とするリソースによって定義されます。進化したエージェントは特定のニッチを効果的に占有し、他のエージェントからの競争に対しても強い優位性を持つことができます。
私たちは最近の研究論文「Agent Skill Acquisition for Large Language Models via CycleQD」において、LLMエージェントの集団を進化させる「CycleQD」を提案しました。このフレームワークでは、それぞれが固有のニッチを持つエージェント群を形成し、複雑なエージェントタスクを効率的に解決します。
従来のLLMのファインチューニング手法とは異なり、私たちの手法はモデルマージ(過去に研究した技術)を進化的なプロセスとして採用します。この手法により、8Bパラメータという比較的小規模なモデルでありながら、特にコンピュータサイエンス分野において高い性能を発揮するAIエージェント群を生成することに成功しました。さらに、この手法は画像認識分野などの言語以外の領域にも適用可能です。
現在のAI開発は、モデルの大規模化に注力する傾向にありますが、そのために必要な計算資源のコストが大きな課題となっています。単一の大規模モデルですべてのタスクをこなすのではなく、それぞれが特化した能力を持つ小規模で「ニッチ」なモデル群を進化させていく手法は、より持続可能なAI開発の道筋となる可能性があります。
CycleQDは、交叉にモデルマージを、突然変異にSVDを採用した、Quality Diversityに基づく進化的なアプローチです。それぞれのタスクに特化したエキスパートモデルの初期集団を元に、一般的な言語能力を損なうことなく、エージェントタスクに優れた多様な小規模モデル群を生み出していきます。
Quality Diversityとは
魔法使いの世界を冒険しながら、さまざまな色や形、味の魔法の豆を集めていると想像してください。最高の魔法の豆をただ1つ見つけることに執着するのではなく、色とりどりの形や味わいの異なる豆をコレクションしていく - これこそがQuality Diversity(QD)の考え方です。QDは進化計算の新しいパラダイムで、「最良の解」を探す従来の手法とは異なり、独自の特徴を持つ優れた多様な解の集合を見つけることを目指します。
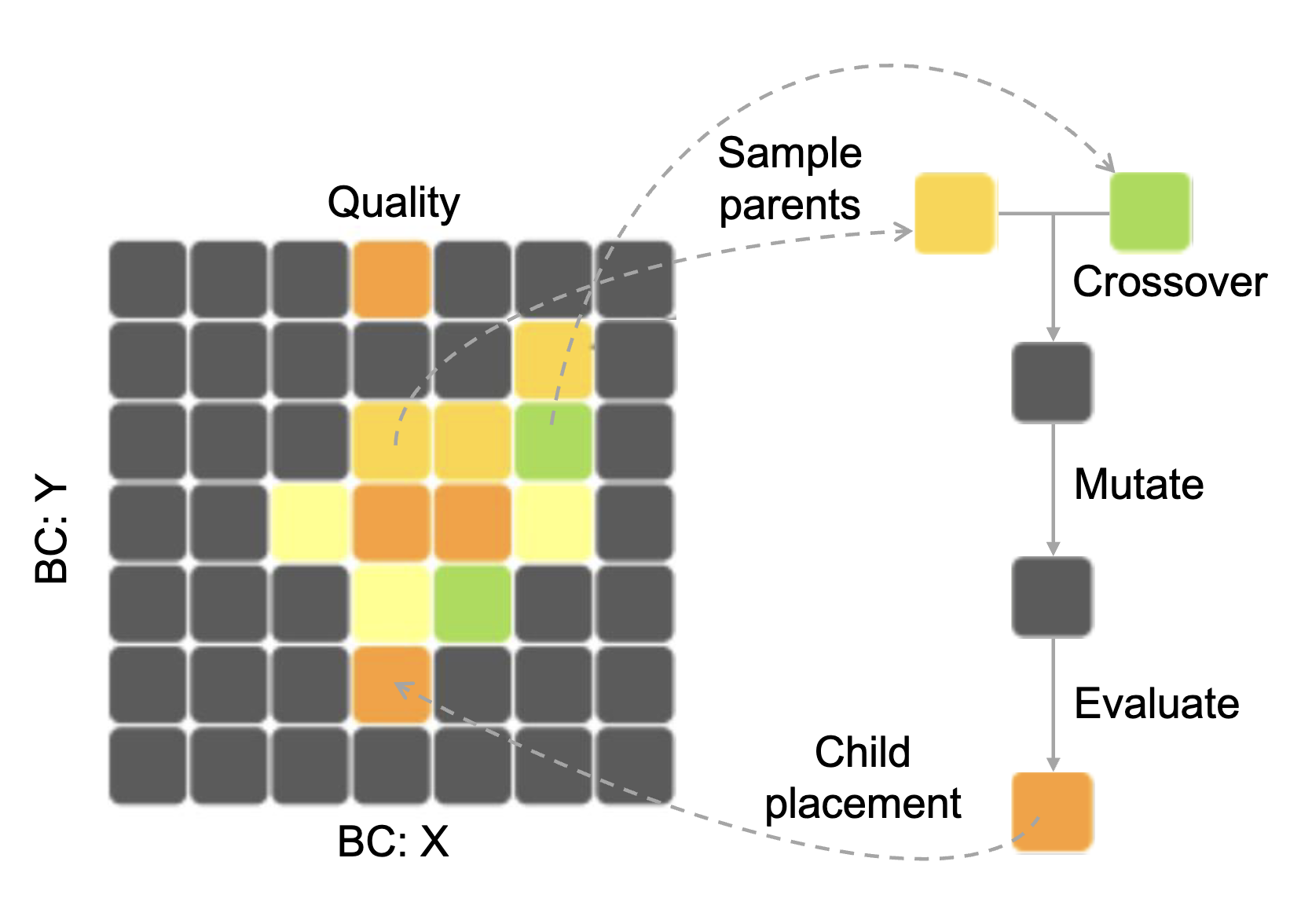
魔法の豆のコレクションボックスを想像してみましょう。このボックスは格子状に区切られており、各格子は豆の特徴(色や魔法の効果など)を表しています。QDの専門用語では、これらの特徴を「行動特性」(Behavior Characteristics, BCs)と呼びます。これは同時にスキルの領域としても捉えることができます。コレクションの目標は、各格子に最適な豆を獲得することです。ここでの「最適」とは、ユーザーが定義した基準(例えば豆の大きさ)に基づいて判断されます。QDではこれを「品質(Quality)」と呼んでいます。
では、より多様な豆をどのように集めていくのでしょうか?ここで進化アルゴリズムを導入します。魔法の世界では、豆から新しい豆が生まれると考えてみましょう。コレクションから2つの「親」となる豆を選び、魔法の力(進化アルゴリズムでは「交叉」や「突然変異」と呼ばれる操作)を使って新しい豆を生み出します。生まれた「子豆」は、その特徴(色や魔法の効果)が評価され、コレクションボックスのどの格子に属するかが判断されます。もし既にその格子にある豆よりも品質が高い(例:より大きい)場合、新しい豆がその格子の代表として置き換えられます。この過程を繰り返すことで、コレクションボックスは徐々に、それぞれの格子に最適な豆で満たされていきます。これがQDの基本的な仕組みです。
CycleQDとは
QDの考え方は、現実世界で新たな視点を提供し、様々な課題を解決します。例えば、教育現場ではSTEM(科学・技術・工学・数学を重視した教育)、スポーツ、人文科学など、様々な才能を育成することで調和のとれた社会を作り上げています。スタートアップ企業では、互いに補完し合う多様な才能を持つチームが成功を収めています。私たちの研究では、このQDの考え方を大規模言語モデル(LLM)の学習に取り入れ、プログラミングやデータベース(DB)操作、OS操作といった複合的なスキルの習得に応用してきました。
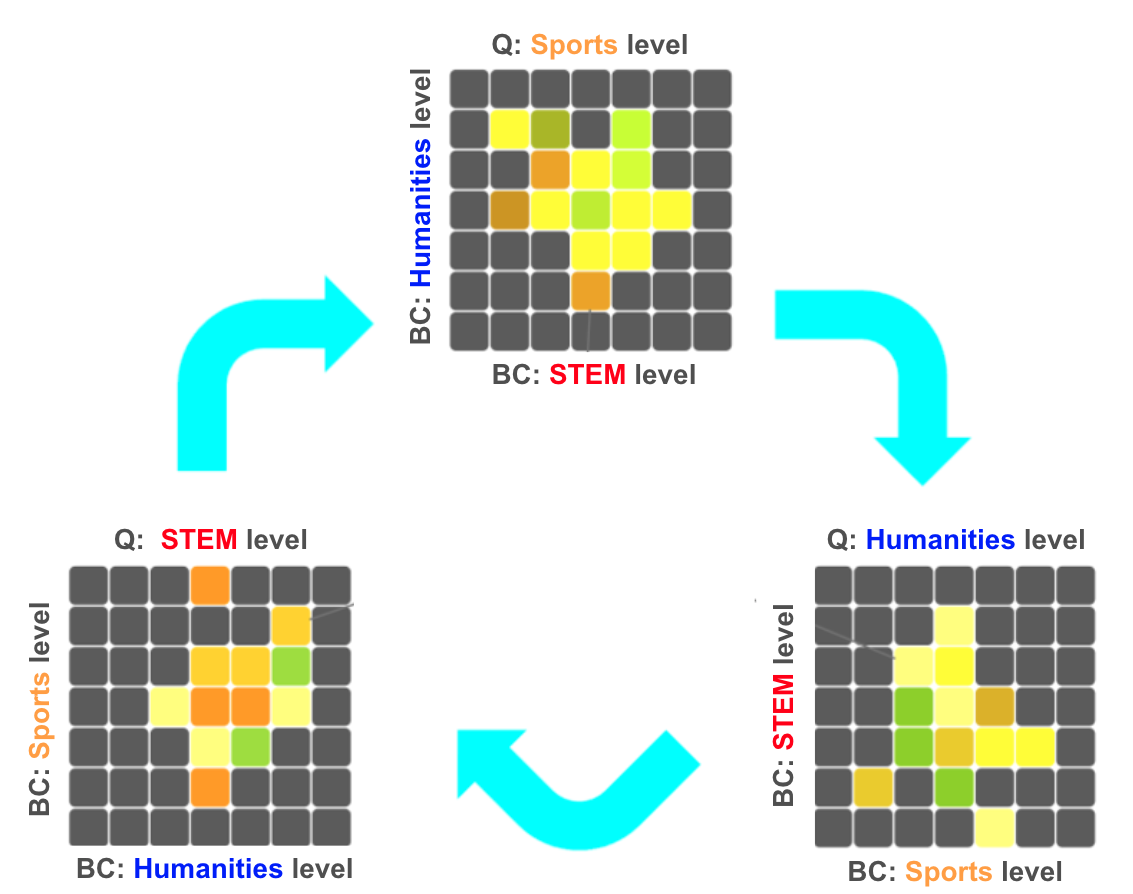
教育現場におけるCycleQDフレームワークの適用イメージ。図の上部では𝑥軸にSTEMの成績、𝑦軸に人文科学の成績をとり、色の濃淡で各学生のスポーツの成績を表現しています。この3つの指標の関係性を周期的に入れ替えることで、様々な観点から学生の総合的な能力を評価することができます。
LLMにこのような複数のスキルを学ばせる際には、これまで主に2つの課題が存在していました:
- データのバランス調整:異なるタスク間で学習データの偏りが生じないよう、適切な配分を保つ必要があります
- 複数スキルの総合的な最適化:特定のスキルだけが突出することなく、全体的にバランスの取れた成長を目指す必要があります
これらの課題に対応するため、私たちは「CycleQD」という新たな手法を開発しました。
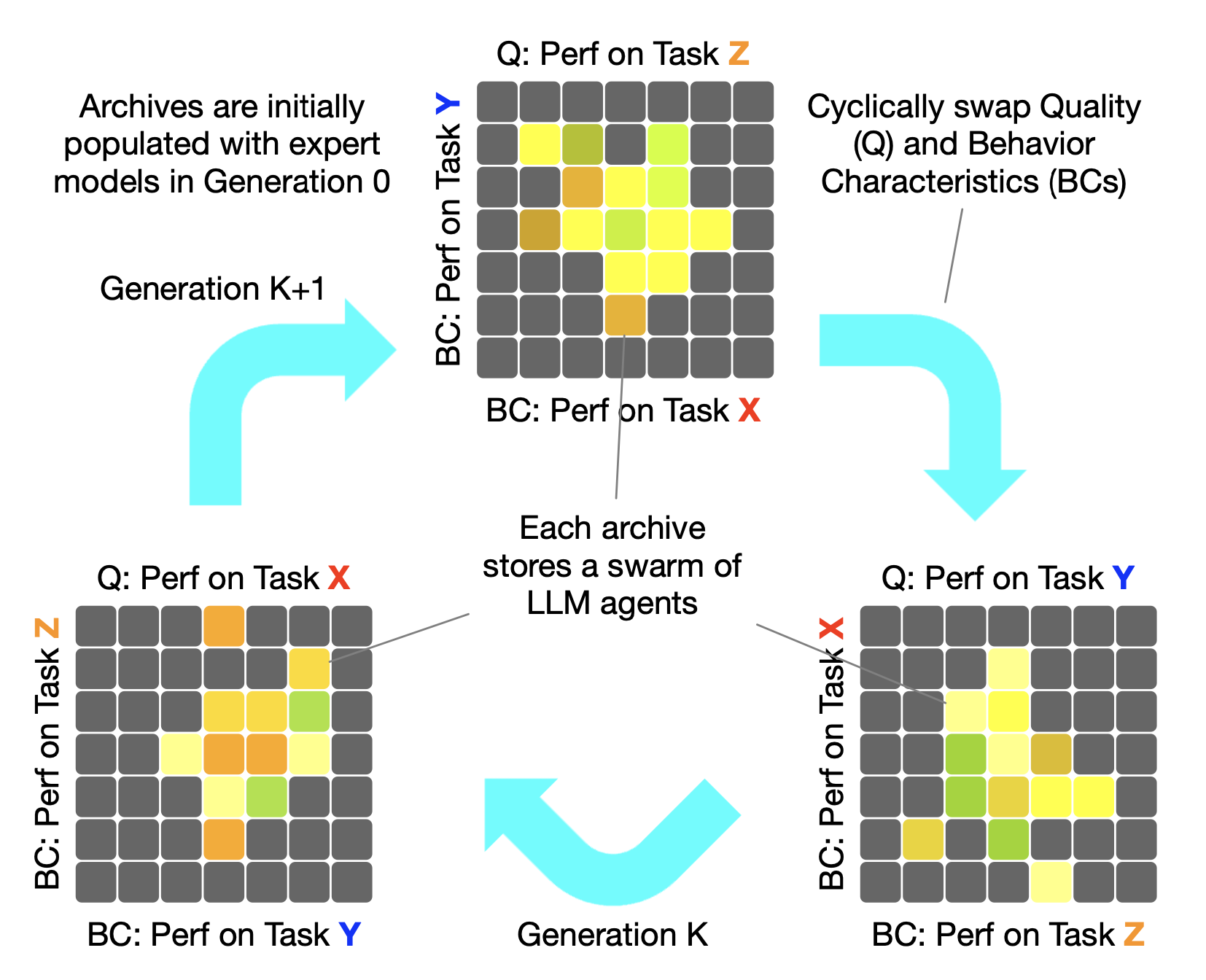
周期的に切り替わる品質と行動特徴
魔法の豆のコレクションボックスが、LLMのコレクションボックスに変わったと想像してください。新しいボックスはもはや2次元の格子ではなく、習得したい各スキルを1つの次元とする K 次元の空間へと拡張されています。各次元は、LLMのスキル(プログラミングやDB操作など)の習熟度を表します。これらのスキルの習熟度は、異なる領域におけるLLMの性能を測る指標となります。学校の成績表に例えると、CycleQDのボックスに配置されるLLMは、各科目(数学:A、スポーツ:A+、文学:B+)のように異なる性能を示すことになります。
CycleQDの特徴的な点は、最適化の焦点を周期的に切り替えていく方法です。新しいLLMを生成する際、一つのスキルを品質(Quality)として選び、そのスキルの向上に焦点を当てます。一方、他のスキルは行動特性(BC)として扱われ、多様性の維持に貢献します。教育を例に挙げると、数学→スポーツ→文学→(再び)数学という循環的な順序で、それぞれのスキルを重点的に改善していきます。このアプローチにより、すべてのスキルが順番に「主役」となる機会を得ます。これによって、特定のスキルだけが突出することなく、バランスの取れたスキルセットを持つLLMの開発が可能になります。上の図は、この仕組みを表しています。
モデルマージによる交叉とSVDベースの突然変異
CycleQDでは、まずK個のスキルそれぞれに特化した専門LLMを用意し、それらをベースに交叉と突然変異を繰り返すことで、品質の高いモデルをコレクションボックスに追加していきます。
モデルマージによる交叉
従来の進化的アルゴリズムでの遺伝子の組み合わせに相当する部分を、LLMのモデルマージにより実現しています。交叉の段階では、ボックスから2つを選んでマージし、新しいLLMを生成します。この手法は私たちの過去の研究で開発したもので、コスト効率が高く、短時間で複数のスキルをバランスよく組み合わせたモデルを生成できる利点があります。
SVDベースの突然変異
モデルにランダムな調整を加える代わりに、「特異値分解(Singular Value Decomposition, SVD)」を使用します。これは、モデルのスキルを基本的な構成要素、いわば「サブスキル」に分解する技術です。例えば、数学を推論能力と計算能力に分解するようなイメージです。この基本要素を調整することで、新しいモデルが親モデルを超えて新たな可能性を探索できるようになります。このアプローチは、過学習を回避しつつ、モデルが局所最適解に陥るのを防ぎ全体的な性能向上に寄与します。
主な結果
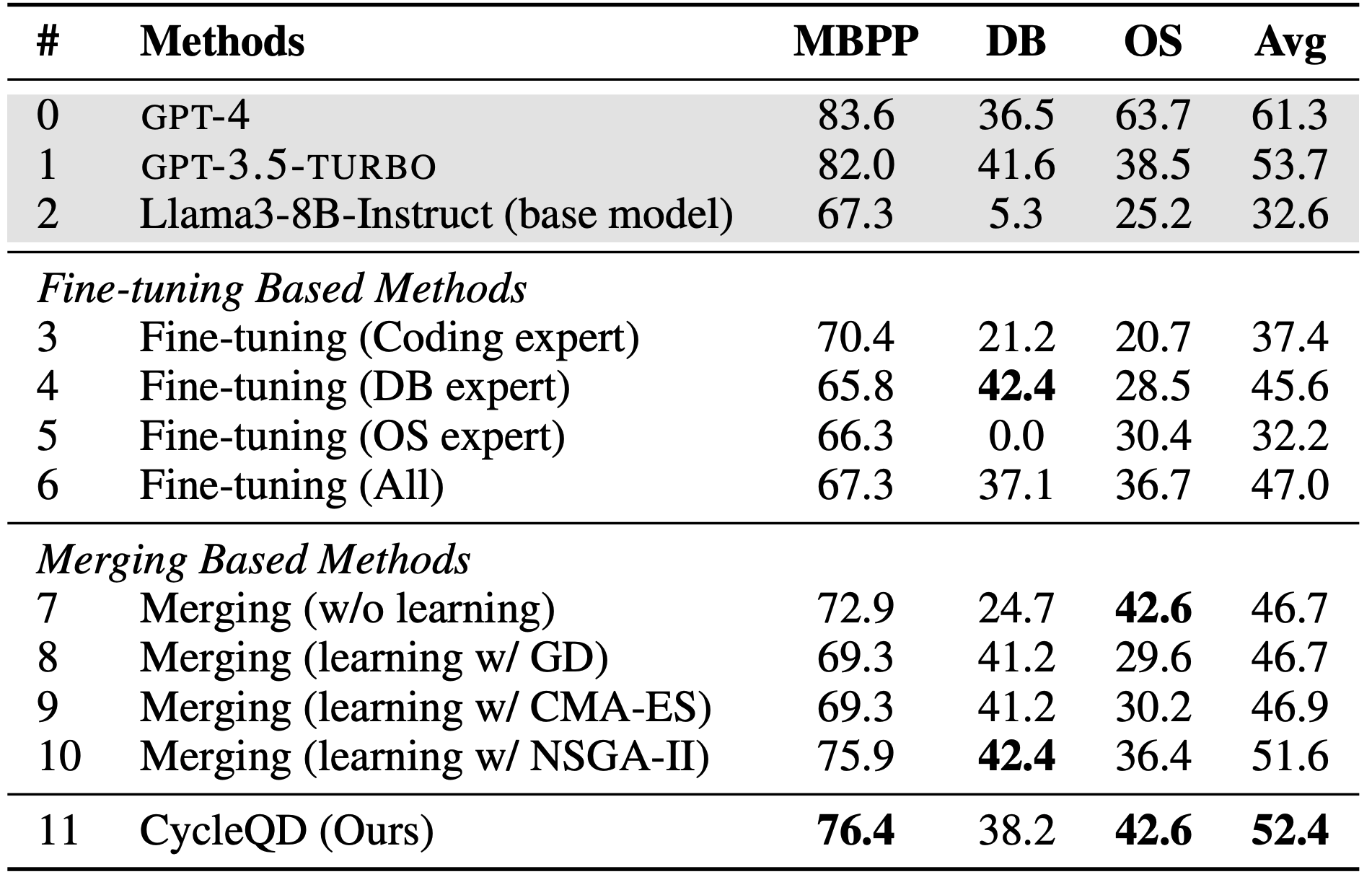
私たちはLlama3-8B-Instructモデルを用いて、コーディング、DB操作、OS操作という3つのコンピュータサイエンスタスク分野のタスクでCycleQDの性能を検証しました。CycleQDは複数のタスクにおいて優れたパフォーマンスを発揮し、従来のファインチューニングやモデルマージ手法を上回る結果を示しました。以下の表に、主要な結果をまとめています。
注:コーディングタスクについては、広く使われているMostly Basic Python Programmingベンチマークを使用したため、MBPPと略記しています。
コンピュータサイエンスタスクにおける評価結果。MBPPはpass@1の値を、DBとOSのタスクは成功率を示しています。ベースモデルとGPTモデル(グレーで表示)も比較のため含めています。GPTモデルを除き、すべてのモデルは8Bパラメータです。
以下の図は実験終了時のCycleQDの結果を2次元に展開して可視化したものです。この図では、各視点で2つの行動特徴(BCs)を軸に取り、グリッド内の色の濃さがモデルの品質(Quality)を表しています。
例えば、下図の中央の図では、x軸がコーディング(MBPP)の性能、y軸がOS操作の性能を表し、各格子の色の違いはDB操作の性能を示しています。
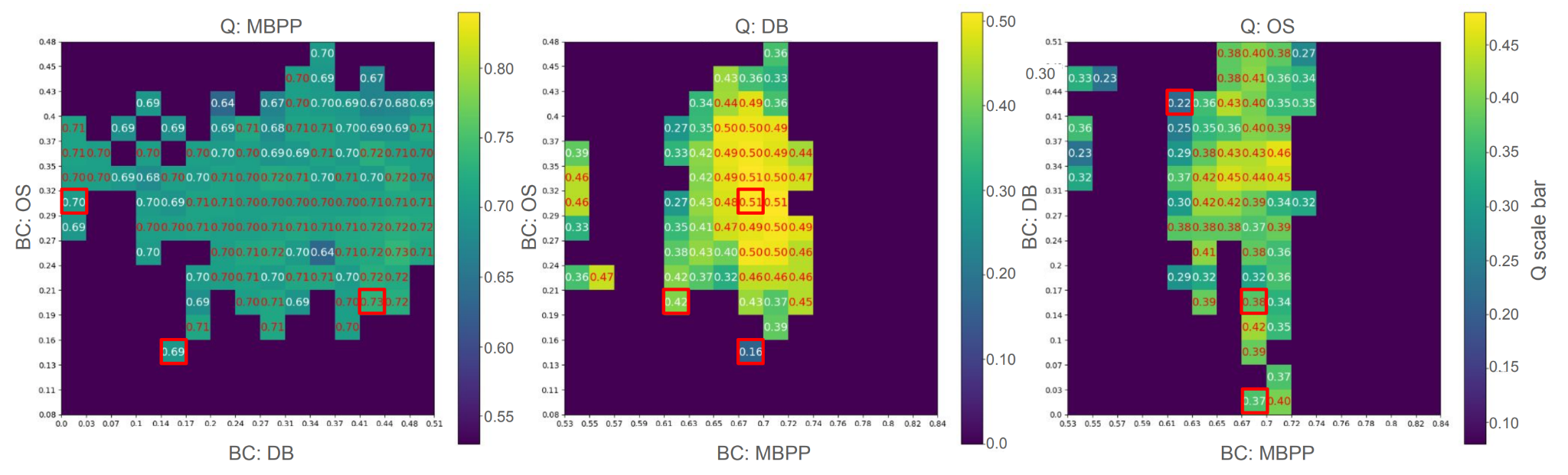
赤い枠で囲まれている箇所は、初期に用意した3つの専門モデルの位置を表しています。ご覧の通り、ボックスは単一のスキルに特化したモデルだけでなく、複数のタスクに対応できる多様なモデルで満たされています。CycleQDが効果的に多様なスキルセットを持つモデル群を生成できることを示しています。
CycleQDは従来の手法と比較して、複数のスキルを同時に習得するという観点で優れた性能を示しました。ファインチューニングや従来のモデルマージ手法との比較、及び詳細な分析をご覧になりたい方は、ぜひ私たちの論文 をご参照ください。
今後の展望:生涯学習とエージェント群
AIの今後の発展において最も重要なテーマの1つは「生涯学習」です。これは、システムが継続的に成長し、適応し、知識を蓄積し続けるプロセスです。CycleQDは、このビジョンに向けた第一歩であり、多様なスキルを獲得することで生涯学習の基盤を築きます。
もう一つの有望な方向性はマルチエージェントシステムです。CycleQDで生成された多様なエージェントを互いに協力させたり、競争させたり、学び合わせることで、新たな可能性が広がるかもしれません。様々な専門スキルと持つエージェントの群れは、科学的発見から現実世界の問題解決まで、AIの新たな地平を切り開く可能性を秘めています。

謝辞
本研究は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)および経済産業省が主催する「Generative AI Accelerator Challenge(GENIAC)」のプロジェクト(JPNP20017)として実施されました。プロジェクトへの採択と支援に深く感謝申し上げます。
Sakana AI
日本でのAIの未来を、Sakana AIと一緒に切り拓いてくださる方を募集しています。当社の募集要項をご覧ください。