
Update (January 28, 2025)
We’re pleased to announce that our paper, “Evolutionary Optimization of Model Merging Recipes,” has been accepted to Nature Machine Intelligence and published today! The latest version includes new experimental results that further validate our approach: Link to our Nature Machine Intelligence publication.
Back in March 2024, Sakana AI released “Evolutionary Model Merge,” which generated some attention in the AI community. It has since been implemented in well-known open-source frameworks like mergekit and Optuna Hub, enabling diverse users to create and publish many unique models. Multiple internal and external teams have been pursuing follow-up research; one example is “CycleQD,” which was accepted to ICLR 2025. We are happy to incorporate all the feedback from the community and from our reviewers, and release additional results into our Nature Machine Intelligence publication.
We view “Evolutionary Model Merge” as the first step in our long-term R&D efforts. Sakana AI will continue to learn from the principles of nature and forge new frontiers in foundational model development. Stay tuned!
Summary
The core research focus of Sakana AI is in applying nature-inspired ideas, such as evolution and collective intelligence, to create new foundation models. We are currently developing technology that makes use of evolution with the goal of automating the development of foundation models with particular abilities suitable for user-specified application domains. Our goal isn’t to just train any particular individual model. We want to create the machinery to automatically generate foundation models for us!
As a first step towards this goal, we’re excited to release our report, Evolutionary Optimization of Model Merging Recipes.
In this release:
-
We introduce Evolutionary Model Merge, a general method that uses evolutionary techniques to efficiently discover the best ways to combine different models from the vast ocean of different open-source models with diverse capabilities. As of writing, Hugging Face has over 500k models in dozens of different modalities that, in principle, could be combined to form new models with new capabilities! By working with the vast collective intelligence of existing open models, our method is able to automatically create new foundation models with desired capabilities specified by the user.
-
We find that our approach is able to automatically discover novel ways to merge different models from vastly different domains (like non-English language and Math, or non-English language and Vision), in non-trivial ways that might be difficult for human experts to discover themselves.
-
To test our approach, we initially tested our method to automatically evolve for us a Japanese Large Language Model (LLM) capable of Math reasoning, and a Japanese Vision-Language Model (VLM).
-
Surprisingly, we find that both models achieve state-of-the-art results on several LLM and Vision benchmarks, while not being explicitly optimized to be good at these benchmarks!
-
In particular, our evolved Japanese Math LLM, a 7B parameter model, to our surprise, achieved the top performance on a vast array of other Japanese LLM benchmarks, even exceeding the performance of some previous SOTA 70B parameter Japanese LLMs! We believe our experimental Japanese Math LLM is good enough to be a general purpose Japanese LLM.
-
Our evolved Japanese VLM is able to handle culturally-specific content remarkably well, and also achieves top results when tested on a Japan-sourced dataset of Japanese image-description pairs.
-
We find our method extends to Image Generation Diffusion Models. We report preliminary results where we evolved a high quality, lightning fast, 4-diffusion-step Japanese-capable SDXL model.
In the end, we applied this method to evolve 3 powerful foundation models for Japan:
- Large Language Model (EvoLLM-JP)
- Vision-Language Model (EvoVLM-JP)
- Image Generation Model (EvoSDXL-JP)
We are excited to release 2 state-of-the-art Japanese foundation models, EvoLLM-JP and EvoVLM-JP, on Hugging Face and GitHub (with EvoSDXL-JP coming up), with the aim of effectively accelerating the development of nature-inspired AI in Japan!
As researchers, we are surprised that our method is able to automatically produce new foundation models without the need for any gradient-based training, thus requiring relatively little compute resources. In principle, we can employ gradient-based backpropagation to further improve performance, but the point of this release is to show that even without backprop, we can still evolve state-of-the-art foundation models, challenging the current paradigm of costly model development.
Visualization of creating a new foundation model by combining parts of existing models. We find the evolutionary approach to be a crucial ingredient for automating the discovery of effective, but unintuitive ways to combine models.
Introduction
The intelligence of the human species is not based on a single intelligent being, but based on a collective intelligence. Individually, we are actually not that intelligent or capable. Our society and economic system is based on having a vast range of institutions made up of diverse individuals with different specializations and expertise. This vast collective intelligence shapes who we are as individuals, and each of us follows our own path in life to become the unique individual, and in turn, contribute back to being part of our ever-expanding collective intelligence as a species.
We believe that the development of artificial intelligence will follow a similar, collective path. The future of AI will not consist of a single, gigantic, all-knowing AI system that requires enormous energy to train, run, and maintain, but rather a vast collection of small AI systems–each with their own niche and specialty, interacting with each other, with newer AI systems developed to fill a particular niche.
Indeed, we are already noticing a promising trend in the open-source AI ecosystem. Open-source foundation models are readily extended and fine-tuned in hundreds of different directions to produce new models that are excellent in their own niches. Unsurprisingly, most of the top performing models on Open LLM leaderboards are no longer the original open base models such as LLaMA or Mistral, but models that are fine-tunes or merges of existing models. Furthermore, open models of different modalities are being combined and tuned to be Vision-Language Models (VLMs) which rival end-to-end VLM models while requiring a fraction of the compute to train.
What we are witnessing is a large community of researchers, hackers, enthusiasts and artists alike going about their own ways of developing new foundation models by fine-tuning existing models on specialized datasets, or merging existing models together. This has led to an explosion of not just a vast array of specialized high performance models, but also the development of a new kind of alchemy, or black art of model merging.

Model merging is a form of alchemy that works!
The successful art of model merging is often based purely on experience and intuition of a passionate model hacker, best illustrated in the above tweet by Omar Sanseviero. In fact, the current Open LLM Leaderboard is dominated by merged models. Surprisingly, merged models work without any additional training, making it very cost-effective (no GPUs required at all!), and so many people, researchers, hackers, and hobbyists alike, are trying this to create the best models for their purposes. If you want to learn more about model merging, we recommend reading this article by Maxime Labonne.
Evolutionary Approach to Model Merging
Model merging shows great promise and democratizes up model-building to a large number of participants. However, it can be a “black art”, relying heavily on intuition and domain knowledge. Human intuition, however, has its limits. With the growing diversity of open models and tasks, we need a more systematic approach.
We believe evolutionary algorithms, inspired by natural selection, can unlock more effective merging solutions. These algorithms can explore a vast space of possibilities, discovering novel and unintuitive combinations that traditional methods and human intuition might miss. If you want to learn more about evolutionary algorithms, we can recommend this blog post.
Below is an example application of a simple evolutionary algorithm to automate the design of a 2D car that travels very far. At first, many designs are produced randomly, leading to many failed designs, but the few that can move forward pass over some of their winning traits to the next generation. After many generations of natural selection, these Genetic Cars can navigate forward efficiently over challenging terrain in its environment. The structure of some of the best evolved designs are often unintuitive, yet highly effective. At the same time, these designs don’t look like they were designed by a person.
Using evolutionary algorithms for automating design is not new. Evolution has successfully been applied to designing space antenna, floor plans, architecture, stronger and lighter parts for spacecraft.
Just like in the above example that utilizes evolution to find combinations of different shapes to form various new car designs naturally selected for the task of driving very far, new foundation models can also be created by applying evolution to find combinations of different parts of different foundation models. In this work, we apply this concept of evolutionary design to evolve new foundation models. Through successive generations (even up to hundreds), evolution will also produce new foundation models naturally selected to perform really well at a particular application domain specified by the user.
In our technical report, we introduce Evolutionary Model Merge, a general evolutionary method to discover the best ways to combine different models. The method combines two different approaches: (1) Merging models in the Data Flow Space (Layers), and (2) Merging models in the Parameter Space (Weights).
Data Flow Space: The first approach is by using evolution to discover the best combinations of the layers of different models to form a new model. In the model merge community, intuition and heuristics are used to determine how and which layers of one model are combined with layers of another model. But you can see how this problem has a combinatorially large search space which is best suited to be searched by an optimization algorithm such as evolution. Below is an example of this approach:
Merging Models in the Data Flow Space (Layers)
Parameter Space: The second approach is to evolve new ways of mixing the weights of multiple models. There are an infinite number of ways of mixing the weights from different models to form a new model, not to mention the fact that each layer of the mix can in principle use different mixing ratios. This is where an evolutionary approach can be applied to efficiently find novel mixing strategies to combine the weights of multiple models. A high level illustration of mixing weights of two different models:
Merging Models in the Parameter Space (Weights)
Both Data Flow Space and Parameter Space approaches can also be combined together to evolve new foundation models that might require particular architectural innovations to be discovered by evolution:
Merging Models in both Data Flow Space and Parameter Space
Given how far the community has gotten to produce high performing models by combining the existing models through human intuition and trial and error, we would like to see how far an automated method like evolution can go by finding new ways to combine the vast ocean of open-source foundation models, especially in domains that are relatively far apart, such as Math and Non-English Language, or Vision and Non-English Language. In fact, when we started tinkering around with the model merging space, we tried to manually merge Japanese language models with Math and Reasoning foundation models, but failed to find good recipes to merge these models from different domains. It was when we tried using evolution to help find better model merging recipes that it became apparent how powerful this technique can be!
Through our experiments, we are able to create new open models with new emergent combined capabilities that had not previously existed. We will now discuss the results of two new models we produced using this automated approach: a Japanese Math LLM, and a Japanese-capable VLM, all evolved using this approach. In addition to the technical challenge of combining a Japanese language model with other models, it is also satisfying to see how evolution might help transform existing foundation models and bring their capabilities to different cultures.
Generating State-of-the-Art Foundation Models for Japan
Thus far, we have presented a novel application of evolutionary algorithms to automate the creation of new foundation models. Our approach operates in both parameter space (weights) and data flow space (layers), allowing for optimization beyond just the weights of the individual models.
We now apply this method to evolve powerful foundation models for Japan. Specifically, we will present 3 models:
- Large Language Model (EvoLLM-JP)
- Vision-Language Model (EvoVLM-JP)
- Image Generation Model (EvoSDXL-JP)
Japanese Large Language Model (EvoLLM-JP)
We first set out to evolve an LLM that can solve math problems in Japanese. Although language models specialized for Japanese and language models specialized for Math exist, there were no models that excelled at solving mathematical problems in Japanese. Therefore, to build such a model, we used an evolutionary algorithm to merge a Japanese LLM (Shisa-Gamma) and math-specific LLMs (WizardMath and Abel).
In our experiments, we allow the evolution process to go on for a couple hundred generations, where only the fittest (the models who score highest in the population on the Japanese math training set) will survive, to repopulate the next generation. Our final model is the best performing model (evaluated the training set) over 100-150 generations of evolution. This model is then evaluated once on the test set.
To measure performance, we used the percentage of correct responses on the Japanese evaluation set of the MGSM dataset, a multilingual version of the well-known GSM8K data set. For optimization using evolutionary algorithms, a different Japanese dataset was constructed and used to prevent over-training and overestimation (for more details, please refer to the paper). Below are the results of the evaluation.
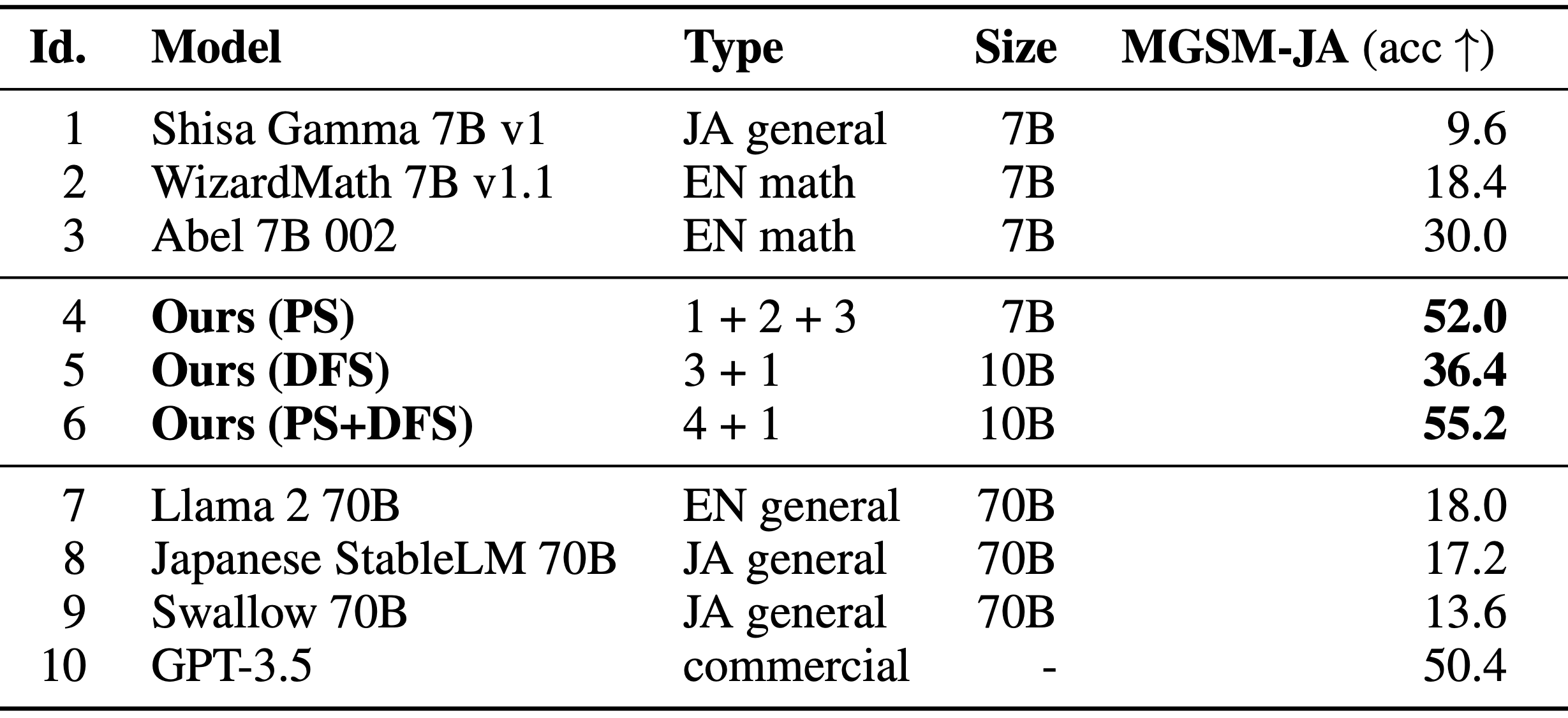
Comparison of LLMs’ performance in solving math problems in Japanese, with MGSM-JA columns showing the percentage of correct answers. Models 1-3 are the original models and models 4-6 are the optimized merged models. Models 7-10 are scores of existing high-performance LLMs for comparison.
The table above reports the results of the evolved LLM models. Model 4 is optimized in parameter space and Model 6 is further optimized in data flow space using Model 4. The correct response rates for these models are significantly higher than the correct response rates for the three source models. From our experience, it is incredibly difficult for an individual to manually combine a Japanese LLM with Math LLMs. But through many generations, evolution is able to effectively find a way to combine a Japanese LLM with Math LLMs to successfully construct a model with both Japanese and math abilities.
In addition, we used the Japanese lm-evaluation-harness benchmark suite to assess not only math ability, but also general Japanese language ability. Surprisingly, we found that these models also achieved high scores on several tasks unrelated to mathematics. It is worth noting that they are not explicitly optimized to perform well on these benchmarks.
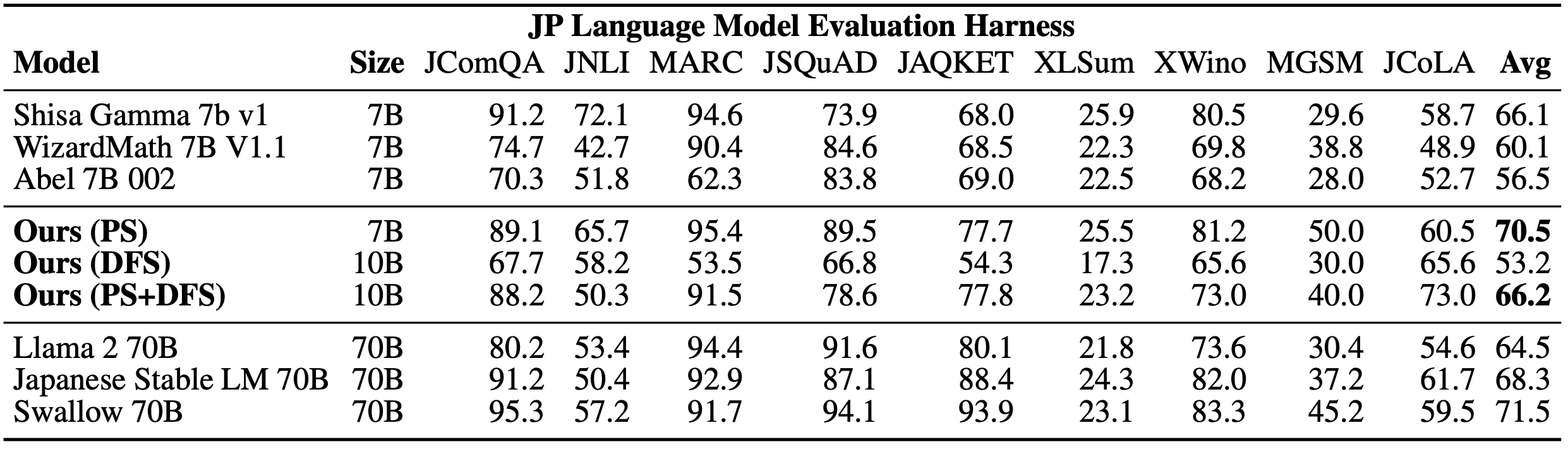
Comparison of LLMs’ overall proficiency in Japanese, where the Avg column is the average of the scores on the 9 tasks, and the higher this is, the higher the overall proficiency in Japanese.
The table above outlines the results of the lm-evaluation-harness assessment, where the Avg column represents the average of the scores on the nine tasks, a widely used indicator of overall Japanese language proficiency. In particular, the 7B EvoLLM-JP achieves a very high score on this index. It exceeds the scores of all Japanese LLMs with less than 70B parameters and even the previous 70B SOTA Japanese LLM score, which is very high considering that it is an LLM with only 7B parameters.
This kind of serendipity is a common recurring theme in our explorations when applying evolution to foundation models. As we later see, evolutionary algorithms naturally “just want to work”. We are able to obtain successful results when attempting to apply the approach to other areas such as VLM and diffusion models even at the early stages of experimentation.
Based on these evaluation results, we believe that our experimental Japanese math LLM is excellent enough to be used as a general-purpose Japanese LLM, and we have decided to release it to the public as EvoLLM-JP. For more information, please refer to our Hugging Face and GitHub.
Our model can produce interesting examples, such as the ability to perform math questions that require specific Japanese-cultural knowledge, or tell Japanese jokes in the Kansai dialect, and we have listed them in the Japanese version of this article.
Japanese Vision-Language Model (EvoVLM-JP)
Evolutionary algorithms not only can discover novel ways of merging LLMs that deal only with text, but also evolve models of different architectures created for different purposes. As an example, we have generated a Japanese vision-language model (VLM) by applying evolutionary model merge.
In constructing the Japanese VLM, we used a popular open-source VLM (LLaVa-1.6-Mistral-7B) and a capable Japanese LLM (Shisa Gamma 7B v1), to see if we can evolve a capable Japanese VLM. To our knowledge, this was the first effort to merge VLMs and LLMs, and here, we demonstrate that evolutionary algorithms can play an important role in the success of the merge. Below are the results of the evaluation.

Comparison of VLM performance. two datasets were used to measure the ability of the VLM to provide accurate answers to image-related questions in Japanese. Higher numbers indicate higher performance. (Note: Japanese Stable VLM uses VA-VG-VQA-500 for training and thus cannot be evaluated on this dataset.)
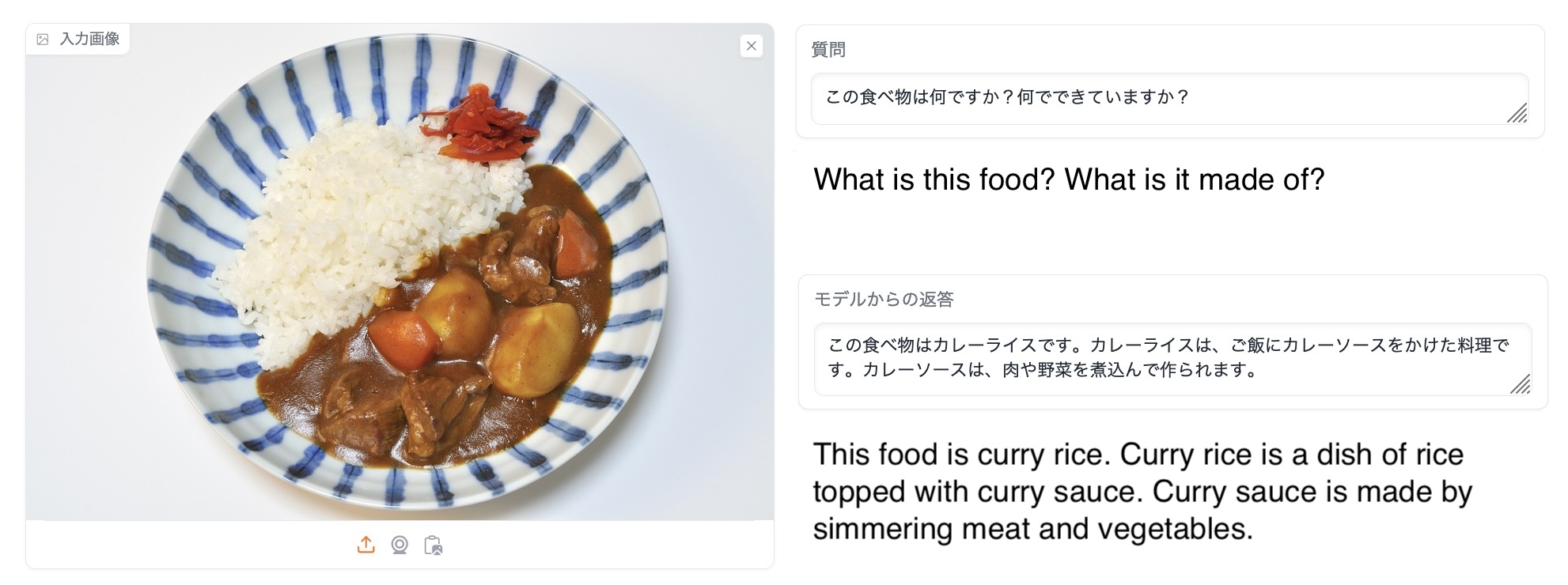
JA-VG-VQA-500 and JA-VLM-Bench-In-the-Wild are both benchmarks for question and answer about images. The higher the score, the more accurate the description is answered in Japanese. Interestingly, our model was able to achieve higher scores than not only LLaVa-1.6-Mistral-7B, the English VLM on which it is based, but also JSVLM, an existing Japanese VLM.
Below are examples of an answer by EvoVLM-JP that we created. Both baseline models often give incorrect answers, while EvoVLM-JP gives appropriate answers. Interestingly, merging the Japanese LLM with the English VLM not only enhanced the model’s Japanese reading and writing skills, but also allowed it to acquire knowledge about Japan. This model has been released on Hugging Face and GitHub along with a Japanese-language Hugging Face demo.
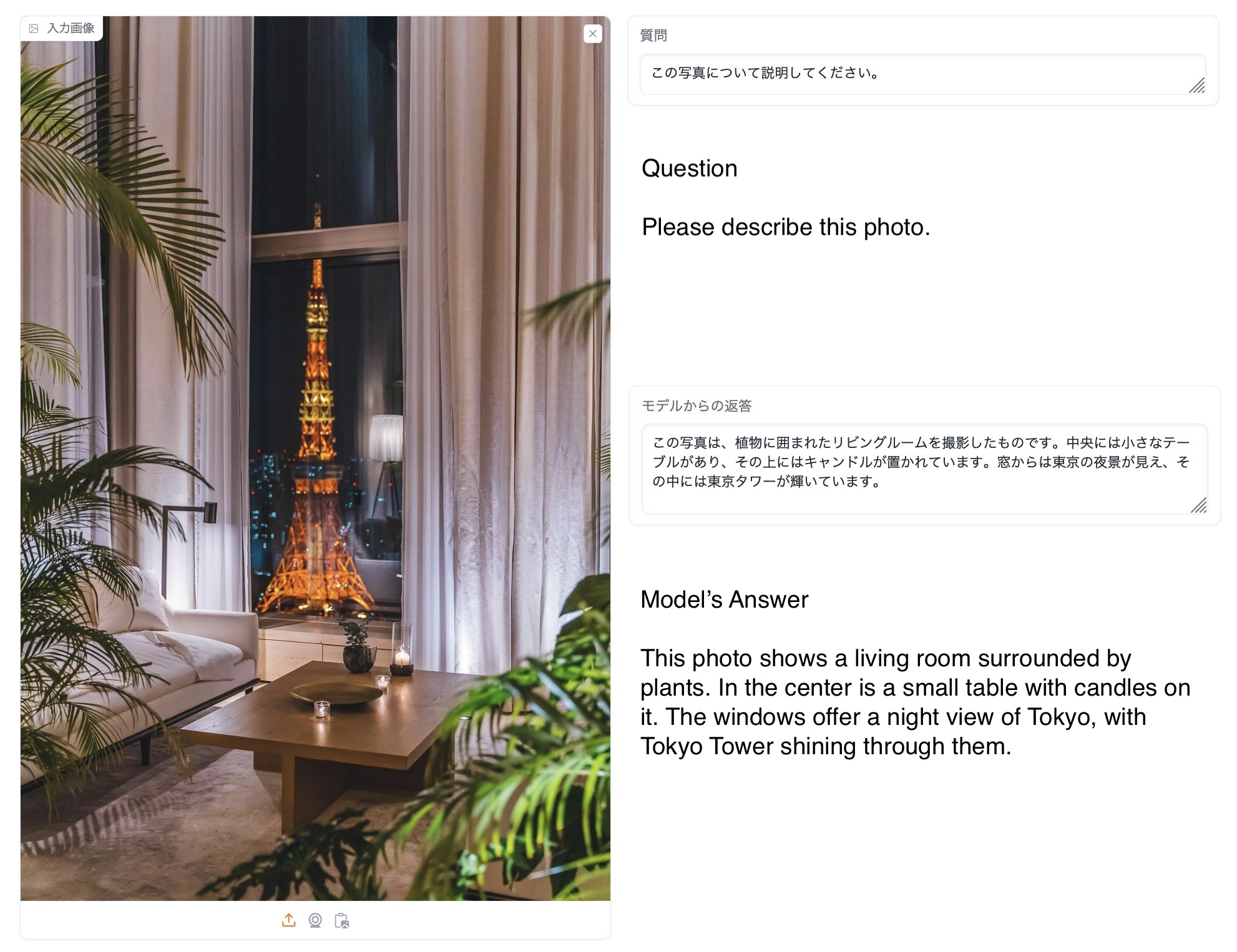
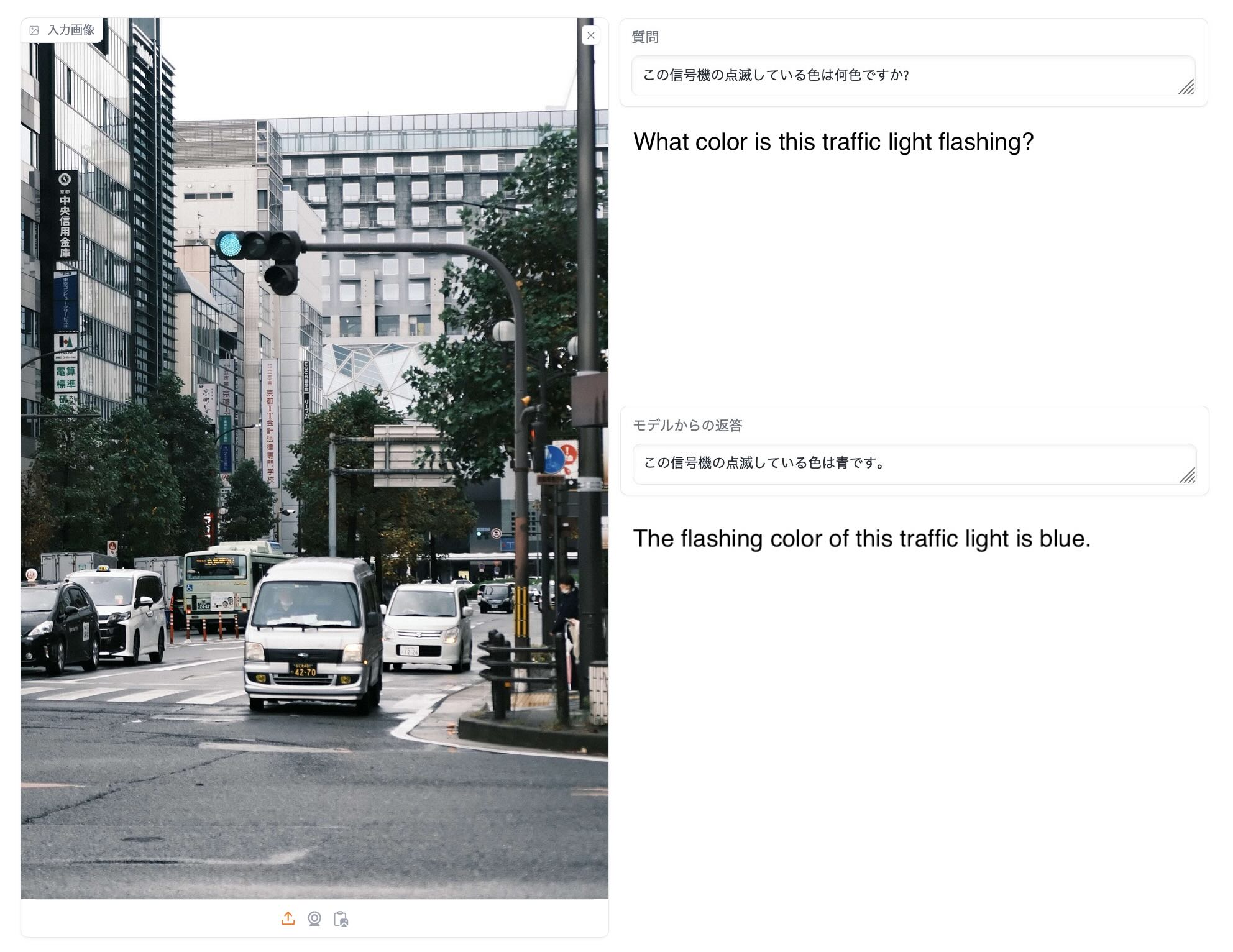
Most other models will output Green as the answer, but EvoVLM-JP responds as Blue. Green is not technically wrong, but in Japanese custom, a traffic light’s “permission to proceed” is described as a “Blue Light”. If you are learning Japanese, or have just moved to Japan, this is one of those weird examples! For some background, read this article.
Japanese Image Generation Model (EvoSDXL-JP)
As one can guess, evolution can also automatically discover ways to merge different diffusion models too!

EvoSDXL-JP 4-step diffusion examples using Japanese language prompts natively , such as:
「味噌ラーメン、最高品質の浮世絵、葛飾北斎、江戸時代。」
(“Miso Ramen, Ukiyoe of the highest quality, Hokusai, Edo period.”)
We are also already achieving promising results when applying evolutionary model merge methods to different image generation diffusion models. In particular, we are able to evolve Japanese-capable SDXL models that are optimized to perform inference in only four diffusion steps, making the generation speeds extremely fast. These results are currently not included in our paper, but will be included in a subsequent release, so stay tuned!
Looking into the Future: The Rise of Evolutionary AI
In this release, we have reported some of our initial progress in making use of evolution to automate the production of foundation models. While the techniques presented here have broad applicability, as an AI lab with roots in Japan, we wanted to first apply these methods to produce best-in-class foundation AI models for Japan. But we think we’re just scratching the surface in terms of exploring the full capabilities of this technology, and we believe this is just the very beginning of an exciting long-term development!
As an AI lab, our main focus is not just to train a single foundation model. Instead, we are currently embarking on a very promising research direction at the intersection of neuroevolution, collective intelligence and foundation models. We are grateful to have the support of the Japanese government through our NEDO Grant award which will let us scale our ideas and experiments on the latest national GPU supercomputing cluster in Japan.
We expect there will be a growing trend in AI development: evolving new models with unexpected abilities by combining existing ones. This is especially exciting when we consider the skyrocketing costs of training massive foundation models from scratch. By leveraging the vast open-source ecosystem of diverse foundation models, large organizations like government institutions and enterprises can explore a more cost-effective evolutionary approach. This lets us develop early stage foundation models faster before committing significant resources to building entirely custom models, if that is even needed at all. It’s essentially getting more out of what we already have, paving the way for quicker innovation cycles.

Sakana AI
Want to take evolutionary computing to the next level? Please see our Careers page for more information.