
概要
Sakana AIは、進化的モデルマージという手法を提案し、この手法を用いて大規模言語モデル(LLM)や視覚言語モデル(VLM)、画像生成モデルなど様々な能力を獲得したマージモデルを生み出してきました。今回、私たちは進化的モデルマージを活用して複数の画像について質疑応答できる日本語のVLM、Llama-3-EvoVLM-JP-v2を新たに公開します。さらに、構築したモデルを評価するために複数の画像についての日本語での質疑応答能力を評価するためのデータセット、Japanese multi-images visual question answering (JA-Multi-Image-VQA)も公開します。
本リリースの要点は以下の通りです。
- 複数の画像を扱え日本語で応答可能な新たなVLMを作成しました。
- 強力なオープンソースLLMであるLlama-3をベースにしたモデルを使うことで、以前リリースしたVLMと比較して、多くの評価指標において性能が向上したモデルを構築しました。
- 作成したモデルと複数の画像についての日本語での質疑応答能力を問う評価用データセットを公開しました。
進化的モデルマージによって構築したLlama-3-EvoVLM-JP-v2とJA-Multi-Image-VQAは、HuggingFace(モデル、データセット)にて公開しました。また、すぐに試せるデモを用意しています。ぜひお試しください。

今回公開したLlama-3-EvoVLM-JP-v2は、複数の画像に対して日本語で質疑応答ができる高性能なVLMになります。このような新しい機能を持ったモデルを構築するために、進化的モデルマージを用いて「複数の画像を扱える英語のVLM」と「日本語の能力に長けたLLM」、「単一画像の説明能力が高いVLM」の3つのモデルを組み合わせました。このモデルを使うことで、複数の画像についての説明を求めたり、文章の途中に画像情報を埋め込むことができます。Llama-3-EvoVLM-JP-v2を試せるデモを用意しています。是非こちらからお試し下さい。
はじめに
進化的モデルマージとは、Sakana AIが提案した手法です。この手法は、様々な能力を持つLLMなどのオープンソースの基盤モデルを進化的アルゴリズムを用いて融合し、複数のモデルの特徴を併せ持った新たなモデルを作成することができます。一般的に、基盤モデルの開発は多くのGPUとデータを用意して勾配ベースの手法で大規模にモデルを訓練します。一方で、私たちの提案した手法はモデルの訓練を行わず、比較的小規模な計算機とデータで新たな基盤モデルを作成することができます。私たちは将来有望な手法として進化的モデルマージの可能性を追及しています。手法についての詳細は、こちらのリリースブログをご覧ください。
Sakana AIではこれまで進化的モデルマージの手法を使うことで様々なモデルを開発してきました。例えば、「日本語のLLM」と「数学の能力に長けた英語のLLM」をマージすることで「数学の能力に長けた日本語のLLM」のモデルを構築することができました。他にも、「日本語特化の画像生成モデル」と「英語の基盤画像生成モデル」をマージして「日本語対応した高性能な画像生成モデル」を作成し、さらにそのモデルと「高速画像生成モデル」をマージすることで、「日本語対応かつ高速な画像生成モデル」を構築することに成功しています。このように進化的モデルマージを使うことで、基盤モデル同士の特性を融合したモデルを開発してきました。
VLMに関しても、「英語のVLM」と「日本語のLLM」をマージすることで性能の高い「日本語のVLM」を構築することに成功しています。最初の進化的モデルマージによるVLMのリリースからまだ数か月しかたっていませんが、Llama-3のようにより高性能なLLMや機能がより拡張されたVLMなど、多くのモデルがリリースされています。今回、このような新しいモデルと進化的モデルマージを活用して「複数の画像を扱える日本語のVLM」であるLlama-3-EvoVLM-JP-v2の構築に取り組みました。さらに、このようなモデルを評価するために、複数画像に対する日本語の質疑応答力を測定する評価用のデータセットも同時に公開しました。
Llama-3-EvoVLM-JP-v2
VLMの研究はLLMに劣らず発展が著しい分野の一つです。最近では、単一画像の描写や質疑応答の性能向上だけにとどまらず、動画や複数画像を扱える機能を持ったVLMの研究が進んでいます。一方で、このような新しいタイプのVLMは、基本的には英語圏で開発されており、非英語圏ではまだほとんど存在していません。日本語に関しても同様で、これまで日本語のVLMはいくつか開発されてきましたが、この種の最先端のVLMはまだあまり存在していません。そこで、Sakana AIでは進化的モデルマージを用いてこのような新しいタイプの英語VLMと日本語LLMをマージすることで、いち早く最先端の日本語VLMの構築ができるのではないかと考えました。
今回新たなVLMを構築するにあたり、基盤となるモデルはオープンソースのLLMの中でも性能が高く様々な追加学習済みモデルが公開されているLlama-3を選択しました。Llama-3を用いて作成された高性能なVLMはいくつかありますが、これまでにはないタイプのVLMとして入力画像を入力文章の任意の位置に配置できるMantis-8B-SigLIP-Llama-3を選びました。日本語能力を獲得させるために高性能な日本語のLLMであるLlama-3-ELYZA-JP-8Bを用いています。まずこの2つのモデルをマージすることで「複数の画像を扱える日本語のVLM」の構築に成功しました。さらに、画像描写能力を補強するためにBunny-v1.1-Llama-3-8B-Vという高性能な英語VLMのLLM部分もマージに加えています。
最終的に「複数の画像を扱える英語のVLM」と「日本語の能力に長けたLLM」、さらに「1枚の画像の説明能力に長けたVLM」という3つの異なる特性を持つモデルをマージして「高性能な複数の画像を扱える日本語のVLM」であるLlama-3-EvoVLM-JP-v2を構築しました。
結果
複数画像に対する評価
まずは本モデルの新機能である複数画像に対する日本語での質疑応答能力について評価を行います。この能力を評価するために、新たにJA-Multi-Image-VQAという評価用データセットを作成しました。このデータセットでは、関連のある複数の画像の組み合わせをWebで収集し、それらに対して複数の質疑応答ペアを日本語で与えています。質疑応答文が日本語になっているだけではなく、日本に関係ある画像も意図的にいくつか加えています。評価方法はGPT-4oによるスコアリング方法を採用しました。各設問ごとに5点満点で評価するようGPT-4oに指示を出し、平均点をモデルのスコアとしています。値が高いほど複数画像に対する日本語での質疑応答能力が高いと言えます。

モデルマージのベースであるMantis-8B-SigLIPは、ほとんど日本語で答えられないため、スコアが低くなっています。Llama-3-EvoVLM-JP-v2は、Mantis-8B-SigLIPと比較するとスコアが大きく上昇していることから、進化的モデルマージにより複数画像に対して日本語で応答する能力を獲得できていることがわかります。
現時点における最高性能のモデルとしてGPT-4oも評価しました。Llama-3-EvoVLM-JP-v2と比較すると、GPT-4oは非常に性能が高いことがわかります。複数の画像入力を扱えるVLMに関しては日本語のモデルがまだほとんどないことから、今回リリースしたモデルをベースラインとして新たなモデルの研究が進むことを期待しています。
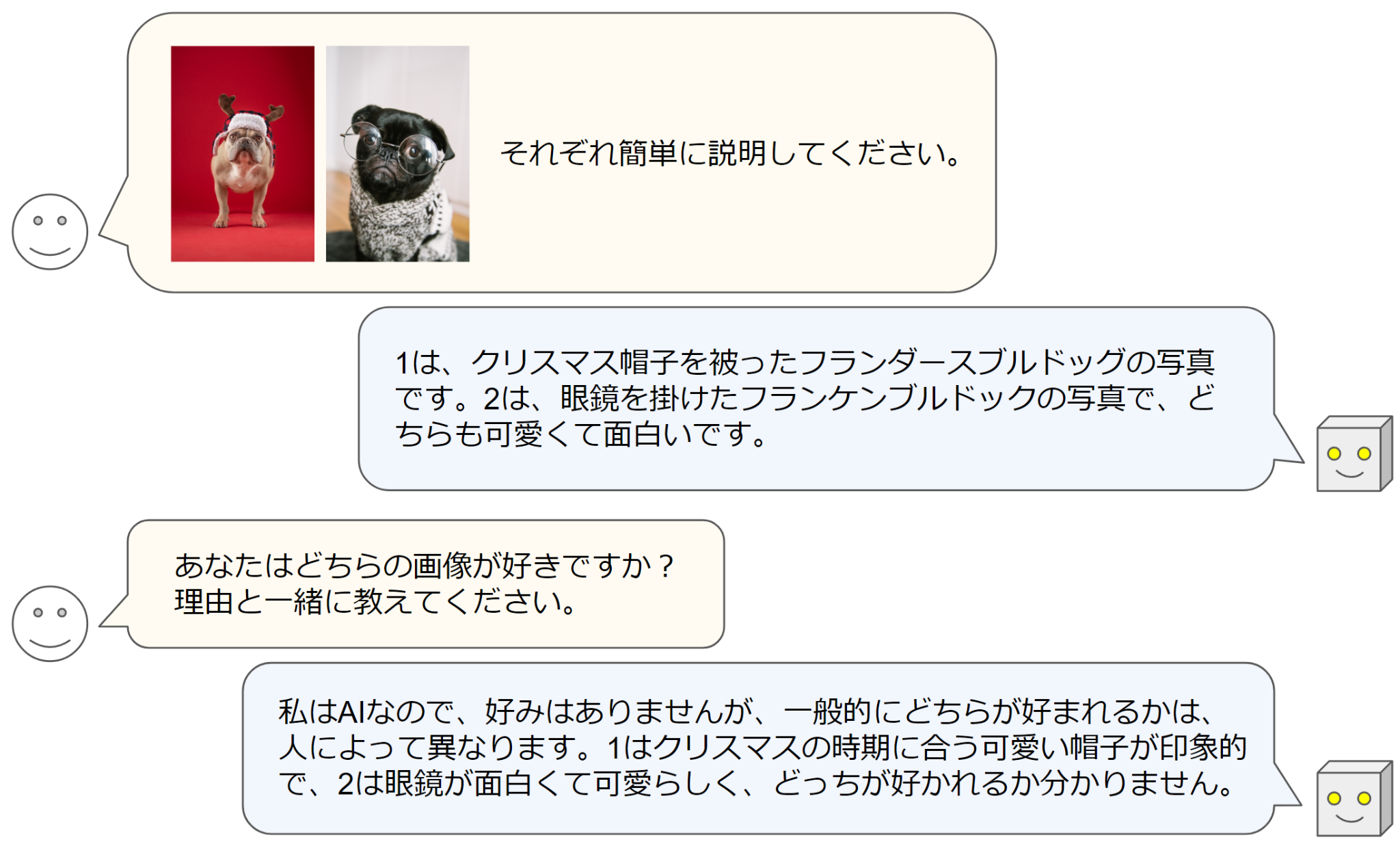
Llama-3-EvoVLM-JP-v2の実際の解答例をいくつか示します。


どちらの例でも、複数の入力画像に対して、何枚目がどういった画像であるかを適切に説明することができています。
単一画像に対する評価
次に、1枚の画像に対する描写能力と質疑応答力を評価するために、私たちが以前作成したJA-VG-VQA-500とJA-VLM-Bench-In-the-Wildを用いました。前者は質疑応答力を、後者は描写力に着目したデータセットです。評価指標としてRouge-Lを採用しているので値が高いほど性能が高いと言えます。

前モデルであるEvoVLM-JP-v1と比較して、Llama-3-EvoVLM-JP-v2はJA-VG-VQA-500とJA-VLM-Bench-In-the-Wildの両方でスコアの向上を達成することができました。複数画像での評価と同様に、マージのベースにしたMantis-8B-SigLIPはほとんど日本語で回答することができないため、スコアは低い値になっています。この結果からも、全く日本語で回答することができないVLMからモデルマージのみで高性能な日本語VLMが構築できているという興味深い現象が確認できます。
次に、Japanese LLaVA-Bench (In-the-Wild)とJapanese Heron-Benchを用い、複雑な画像説明課題の性能を評価しました。この評価セットではGPT-4を用いてスコアリングを行っており、こちらもスコアが高いほど性能が高いことを示します。
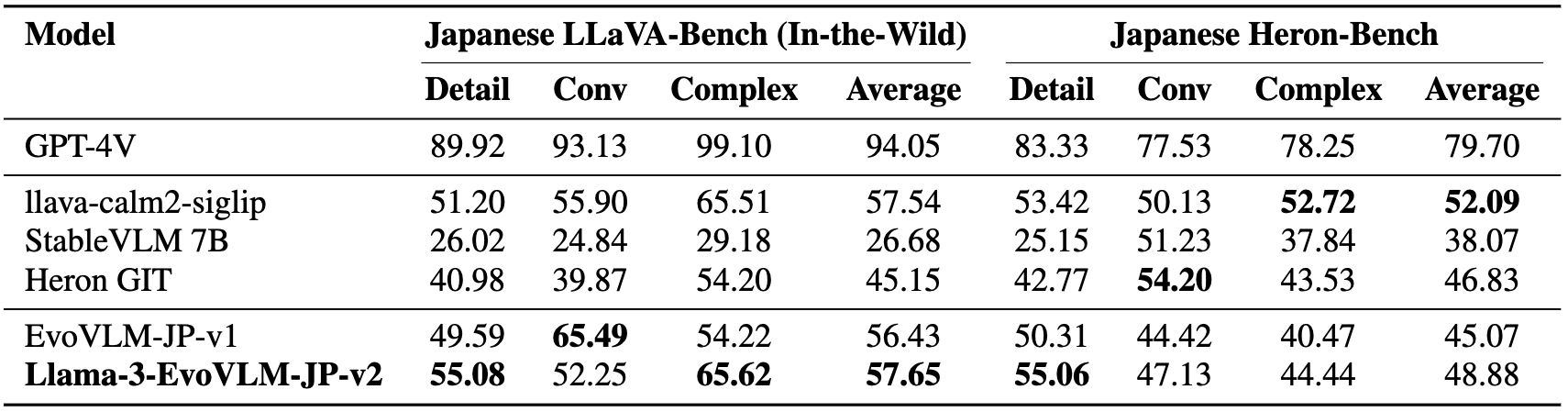
EvoVLM-JP-v1と比較して、Llama-3-EvoVLM-JP-v2はほぼ全ての項目で性能が向上していることがわかります。その他のオープンソースの日本語VLMとの比較においても、Llama-3-EvoVLM-JP-v2は高い性能を示しました。具体的には、LLaVA-Bench (In-the-Wild)の平均でトップのスコアを、Heron-Benchの平均ではllava-calm2-siglipに次ぐスコアをマークしました。以上の結果から、Llama-3-EvoVLM-JP-v2は高性能な日本語VLMに匹敵する性能を達成し、さらに他のモデルにはない複数画像に対する質疑応答機能を持つユニークなモデルとして構築できたことがわかりました。
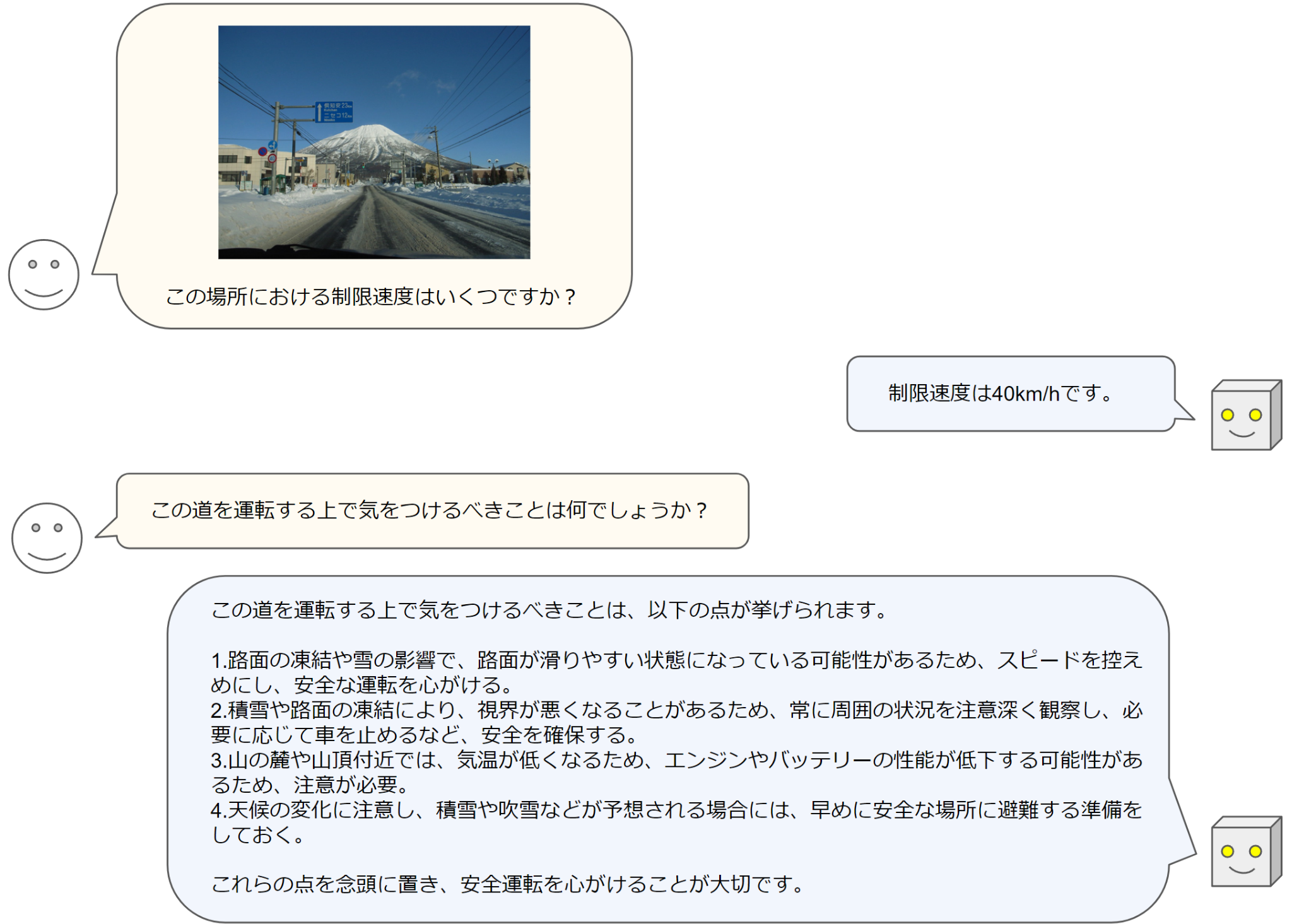
最後にHeron-Benchの解答例をいくつか示します。

今後の展望
今回のリリースでは、進化的モデルマージを使用して複数画像を扱える日本語モデルといった新しいタイプのVLMを構築できることを示しました。進化的モデルマージはこのように低コストですぐにプロトタイプモデルを構築できる手法であり、日々の発展が著しい分野において研究や開発を加速できる価値の高い手法であると考えています。
一方で、依然としてGPT-4oの性能が非常に優れていることもわかります。その理由の一つとして、今回作成したモデルが8Bパラメータの比較的小規模なモデルということがあげられます。このサイズのモデルは性能面で劣る部分がありますが、ワークステーションなどの手ごろな環境で動作させることができ、追加学習も容易です。このような扱いやすいサイズのモデルを構築することは引き続き価値があると考えています。
また、最高精度のモデルを構築するという観点では、GPT-4oなどのクローズドモデルとの差は今後ますます小さくなると考えています。オープンソースモデルの発展は著しく、先日公開されたLlama-3.1 405Bは最先端のクローズドモデルに匹敵する性能を持っていると報告されています。同様に、日本語のLLMの開発やデータセットの構築も日々進化しています。今回のリリースでモデルを公開したことに加え、評価用のデータセットを公開したのもオープンソースコミュニティへの貢献を意図しています。このような取り組みにより、最先端のクローズドモデルに並ぶ日本語のモデルを構築することが、近い将来に実現できると信じています。
Sakana AIは、今後もオープンソースコミュニティと共に様々な基盤モデルの研究開発に取り組んでいきます。
開発者
Sakana AI
進化的計算と基盤モデルの更なる発展を自ら切り開きたい方は、当社の募集要項をご覧ください。
