
This is the second in a series of blog posts presenting the results of Sakana AI’s research projects that were supported by the Japanese Ministry of Economy, Trade and Industry’s GENIAC supercomputing grant.
Summary
At Sakana AI, we draw inspiration from nature to extend the capabilities of foundation models. This was evidenced in our recent work on improving performance with evolutionary model merging, discovering qualitative and diverse agentic skills, and uncovering new ways for LLMs to contribute to AI research.
Following on in this line of research, our latest breakthrough, detailed in our paper, An Evolved Universal Transformer Memory, introduces a revolutionary memory system for transformers, inspired by how human memory selectively retains and prunes information. Our learned memories not only boost both performance and efficiency of existing, pre-trained transformers, but are also universally transferable across different foundation models, even beyond language, without any re-training!
Memory is a crucial component of cognition, allowing humans to selectively store and extract important information from the ceaseless noise dominating our lives. In contrast, transformer foundation models lack this ability and are forced to store and process all past inputs indiscriminately, with severe consequences for their performance and costs during extended tasks.
Imagine transformers that not only “remember” what matters most but also actively “forget” redundant details, leading to smarter, faster and more adaptable models. This is exactly what our work achieves, and here’s what makes it a game changer:
- A new kind of memory: Neural Attention Memory Models (NAMMs) optimize how transformers store and retrieve information, unlocking unprecedented efficiency and performance.
- Supercharged results: With NAMMs, transformers achieve superior results across a wide range of language and coding tasks while requiring less memory.
- Cross-domain mastery: Trained solely on language, NAMMs can be applied to vision, reinforcement learning, and other domains without additional training.
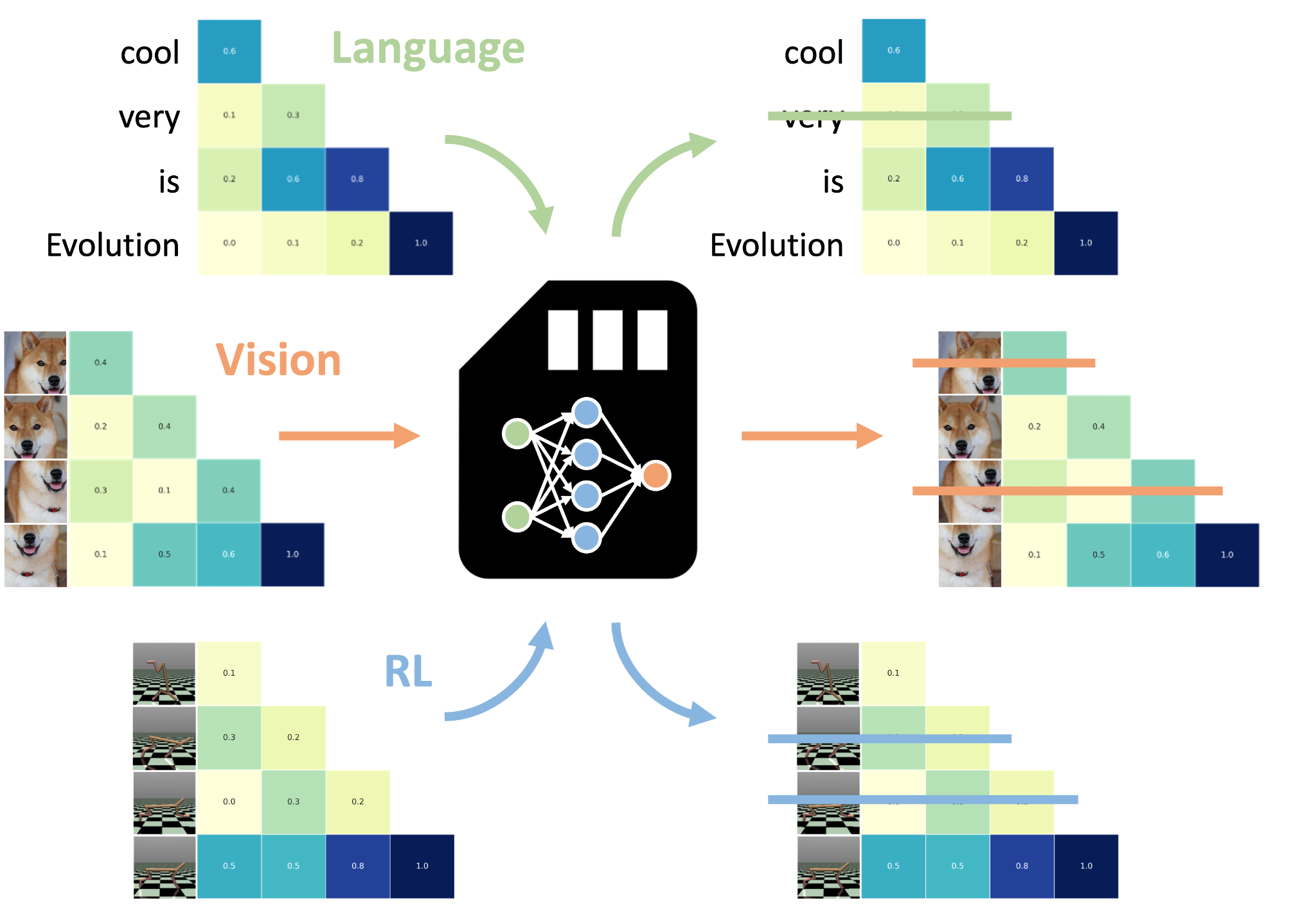
Fully evolved NAMMs trained on language can be zero-shot transferred to other transformers, even across input modalities and task domains!
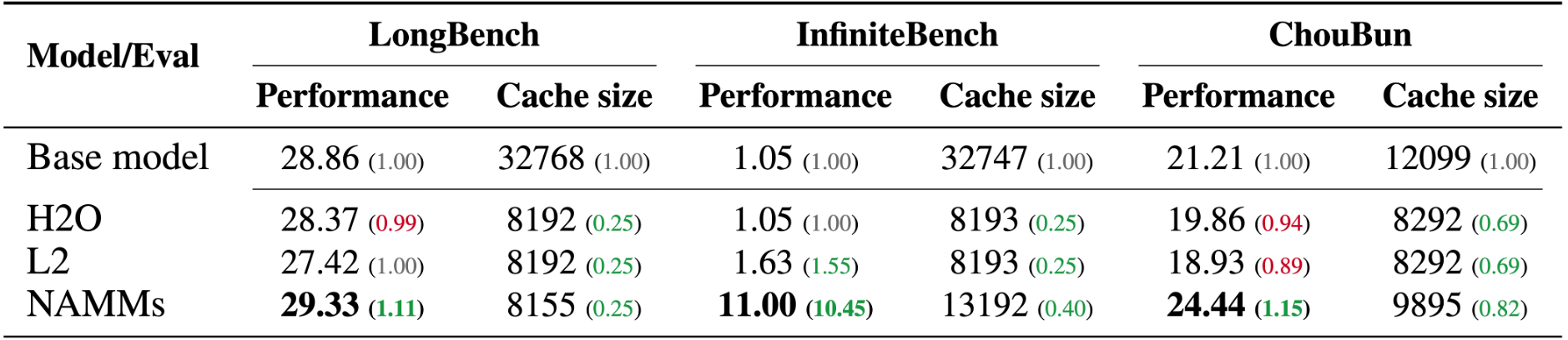
Together with our paper, we share our full training code on GitHub and release ChouBun: a new benchmark designed to evaluate the long-context capabilities of language models in Japanese, addressing gaps in existing benchmarks focused on long content in English and Chinese.
Transformer architectures have become the golden standard in deep learning, with ubiquitous applications in the design of modern foundation models, exhibiting exceptional performance and scalability. The outputs of a transformer are exclusively conditioned on a recent context of input tokens, which for language models (LMs) generally correspond to a window of preceding words. Thus, this context can be viewed as the transformer’s “working memory” containing the latest inputs relevant to its current application.
The information contained in this working memory has been shown to affect the performance of transformers quite significantly. For example, even just carefully modifying the input text with prompt engineering allows LMs to potentially unlock entirely new capabilities, performing tasks outside their training data.
However, providing the ability to handle long contexts also immediately impacts training and inference costs, with modern transformers being increasingly resource-hungry and expensive. Many recent methods proposed to partially offset these costs by studying the effects of dropping subsets of tokens in the memory context with carefully hand-designed strategies. As a result, they showed early success at improving efficiency, yet, at the expense of the original model’s performance.

Learning a Memory Framework with Evolution
In direct contrast, our work departs from prior approaches that relied on fixed rules or handcrafted strategies by introducing Neural Attention Memory Models (NAMMs). NAMMs are simple neural network classifiers trained to decide whether to “remember” or “forget” for each given token stored in memory. This new capability allows transformers to discard unhelpful or redundant details, and focus on the most critical information, something we find to be crucial for tasks requiring long-context reasoning.
However, training NAMMs poses a key challenge as any decision made by our memory models has a binary outcome: each token is either kept in memory or forever lost. This introduces a non-differentiable aspect to the problem, making traditional training techniques, using gradient-based optimization, unsuitable.
Evolution, on the other hand, does not require any gradients and is able to excel in these scenarios. By iteratively mutating and selecting the best-performing models via trial-and-error, evolution algorithms enable us to optimize NAMMs for efficiency and performance, even in the face of non-differentiable operations.

We optimize NAMMs with evolutionary optimization, iteratively mutating and selecting the network parameters yielding the best language modeling performance with our new memory system.
A critical ingredient behind NAMMs lies in their use of attention matrices, key components that are common to any layer of any transformer. These matrices encode the importance of each token relative to others, making them an ideal input to decide which tokens to forget. Due to these properties, by relying solely on the attention matrices we can directly apply a single NAMM across the model’s layers and even transfer the same NAMM to other transformers without any further training. This unparalleled transfer property is not limited to LMs but also applies to foundation models dealing with entirely different input modalities and problem settings (e.g., computer vision, robotic control).
On a technical note, there are three main steps in the execution of NAMMs:
- Processing attention sequences – the attention values for each token in memory are converted to a spectrogram: a frequency-based representation that has been very well established across fields such as audio, medicine, and seismology.
- Compressing the information – the produced representations are then compressed with an element-wise exponential moving average (EMA): condensing the data into a compact, fixed-size feature summary of the history of each token’s attention values.
- Deciding what to remember – NAMMs then use these features as inputs to their learned neural network classifier: outputting a score to decide which tokens to ‘forget’ and allowing the transformer to focus on the most relevant information for its task.
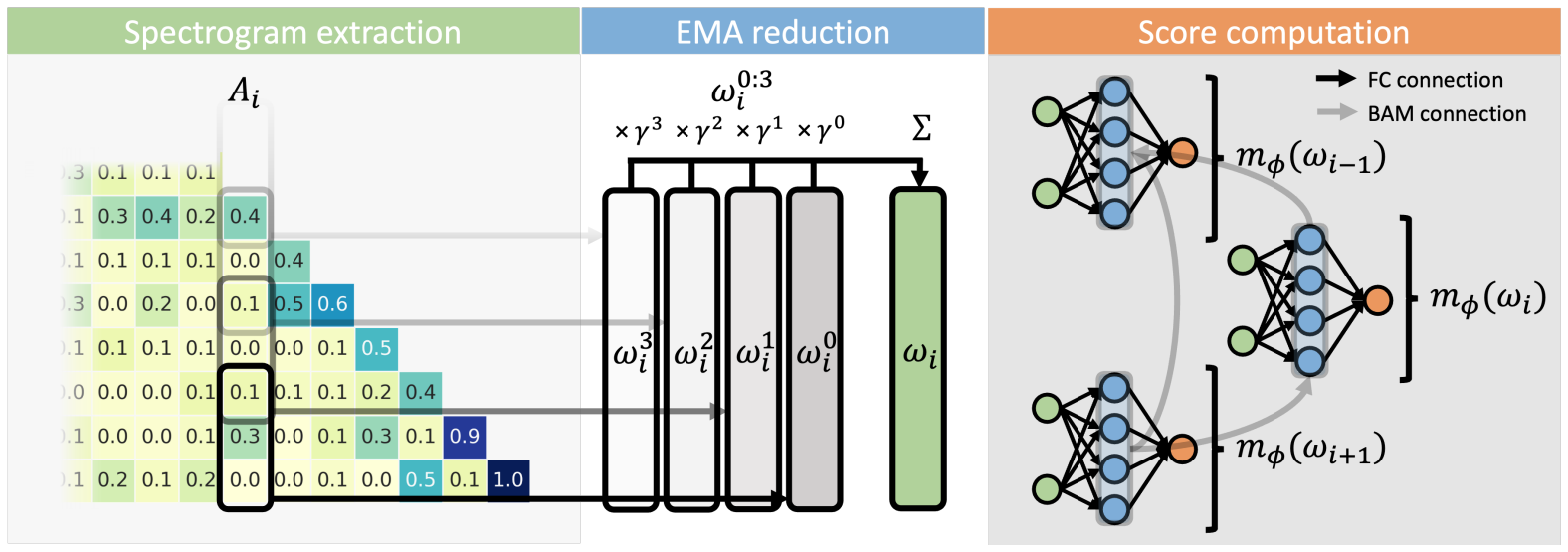
Schematic description of the three main steps in the execution of NAMMs: Processing attention sequences into spectrograms (left), compressing the information with EMA (center), and computing scores to decide what to remember (right).
Applications in Language and Beyond
We train NAMMs on top of a Llama 3 8b base model and thoroughly evaluate this powerful memory-augmented LM on LongBench, InfiniteBench, and our own ChouBun: three benchmarks assessing the ability of LMs to process information over very long input text to answer natural language and coding problems, totaling 36 different tasks. We compare NAMMs with H₂O and L₂, two prior hand-designed methods for memory management.
Across our benchmarks, NAMMs provide clear performance improvements to the Llama 3 8b transformer. Furthermore, our memory systems yield notable side benefits, reducing the context size of each layer, while never being explicitly optimized for memory efficiency. While the prior baselines also notably reduce the context sizes, these efficiency gains often come at performance costs - in line with their stated objective of retaining rather than improving the original full-context performance.
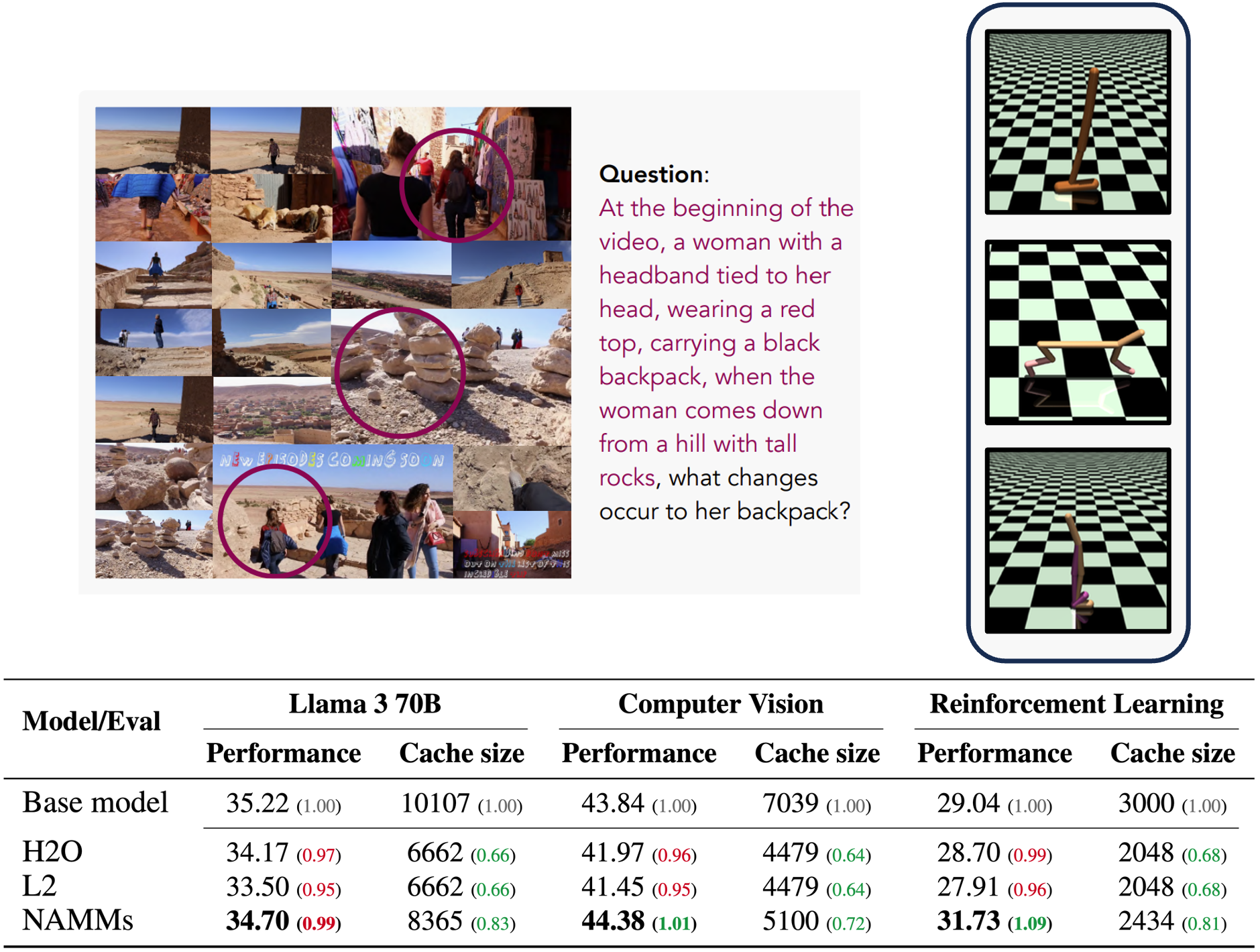
We show that the generality of our conditioning enables zero-shot transfer to entirely new base models. In particular, we evaluate our NAMMs atop a large Llama 70B LM and also transformers designed for different modalities, such as Llava Next Video and the Decision Transformer, tackling computer vision and reinforcement learning tasks. Even in these out-of-distribution settings, NAMMs retain their benefits by discarding tokens such as redundant video frames and suboptimal actions, allowing their new base models to focus on the most relevant information to improve performance.
By analyzing the remembered and forgotten tokens, we find that NAMMs remember different tokens across the layers of transformers. In early layers, NAMMs retain “global information” such as the task preamble and keywords. Instead, in later layers, NAMMs seem to forget many of these tokens, whose information has been already incorporated, focusing more on “local” details and notions contained in the text.
Furthermore, we find that the behavior of NAMMs differs based on the task. In coding tasks, the pruned tokens are mostly contiguous chunks of text, corresponding to whitespace, comments, and unnecessary segments of boilerplate code. Instead, in natural language tasks, NAMMs forget many tokens mid-sentences from the grammatical redundancies of the English syntax, allowing LMs to focus on important names and key concepts.

Comparing the behavior of NAMMs across two layers of a transformer-based language model, for either a natural language (light green) or coding task (light coral).
The Future: An Iterative Process of Learning and Memory Evolution
In our paper, we introduced Neural Attention Memory Models for learning the memory system of transformer-based foundation models. By evolving NAMMs on top of pre-trained language models, we demonstrated their effectiveness across diverse long-context tasks in three languages, surpassing what was previously possible with hand-designed memory management approaches. We also showed that our models inherently possess zero-shot transferability across architectures, input modalities, and task domains.
Looking ahead, this work has only begun to tap into the potential of our new class of memory models, which we anticipate might offer many new opportunities to advance future generations of transformers. For instance, we believe that learning transformers directly on top of NAMMs is an exciting unexplored direction that could open the doors to efficient training over much longer data sequences. Pushing this idea even further, iteratively alternating between learning and evolution could scale these benefits across future generations of foundation models, in a way akin to the iterative process that shaped the development of our very own cognitive memory system.

Acknowledgement
We extend our heartfelt gratitude to the New Energy and Industrial Technology Development Organization (NEDO) and the Japanese Ministry of Economy, Trade and Industry (METI) for organizing the Generative AI Accelerator Challenge (GENIAC) and for selecting us as one of the participants. This project, JPNP20017, was made possible through the support provided by this initiative.
Sakana AI
Interested in joining us? Please see our career opportunities for more information.