
人工知能の次なるパラダイム
大きな技術的飛躍は、ありあまる資源のなかからよりも、むしろ厳しい制約のなかから生まれてきました。人間の認知は、無限の計算資源を備えた脳から生まれたわけではなく、限られた資源のもとで進化が長く積み重なってきた結果として形づくられたものです。日本の製造業が世界で競争力を持てたのも、天然資源の豊かさからではなく、工場という仕組みそのものを継続的に作り変えてきたからでした。
私たちは、AIにも同じ原理が働くはずだと考えています。単体のモデルにデータと計算資源を注ぎ込んで巨大化させていく現在のアプローチは、ここまで多くの成果を生んできました。しかし、その延長線上だけがAIの未来というわけではありません。制約のなかで、集合的に自己を改善し続けるオープンエンドなシステムにこそ、次の段階の鍵があると私たちは見ています。こうした見方は、いまや私たちだけのものではありません。2026年に入り、自己改善型AIを掲げるスタートアップが世界各地で相次いで立ち上がり、「自らを作り変えるAI」という発想は業界全体が向かう大きな潮流になりつつあります。
かつての製造業と同じように、人工知能の時代を迎えるいま、これは日本にとってもひとつの機会だと、私たちは考えています。計算規模で世界最上位の国と張り合うのが難しくても、新しいAIの仕組みを生み出す研究開発においては、日本には大きなチャンスがあります。
Sakana AIは、現代の基盤モデルを取り入れた再帰的自己改善(Recursive Self-Improvement、RSI)技術に、ごく早い段階から取り組んできた研究機関のひとつです。本日、私たちは、AIの開発プロセスそのものを設計し直すことを担う専任の研究グループ「Sakana AI RSI Lab」の始動を発表します。
RSIの土台を築いてきた2年間
RSIの可能性は、いまや業界で広く語られるようになりました。2026年に入ってからは、この考え方を掲げる新しい組織が世界各地で次々と立ち上がっており、そのなかには、私たちがこれまで積み重ねてきた研究を土台として出発した取り組みもあります。こうした動きからは面白い萌芽的な成果が次々と生まれはじめていますが、それがRSIの実現に向けて体系的に動き出すのは、まさにこれからです。
私たちはこの2年間、それを実際に動くシステムとして作り出すことに、一貫して取り組んできました。RSI Labはゼロから始まるわけではありません。これまでの研究は、ひとつの循環を段階的に組み上げてきた成果です。すなわち、エージェント用途のために設計されたモデル(Agent Native Model)が、研究を自動で行うAI(AI Scientist)を生み、そのAIが、さらに優れたモデルを生み出す、という循環です。
Sakana AIのRSI研究の歩みの一部を紹介します。
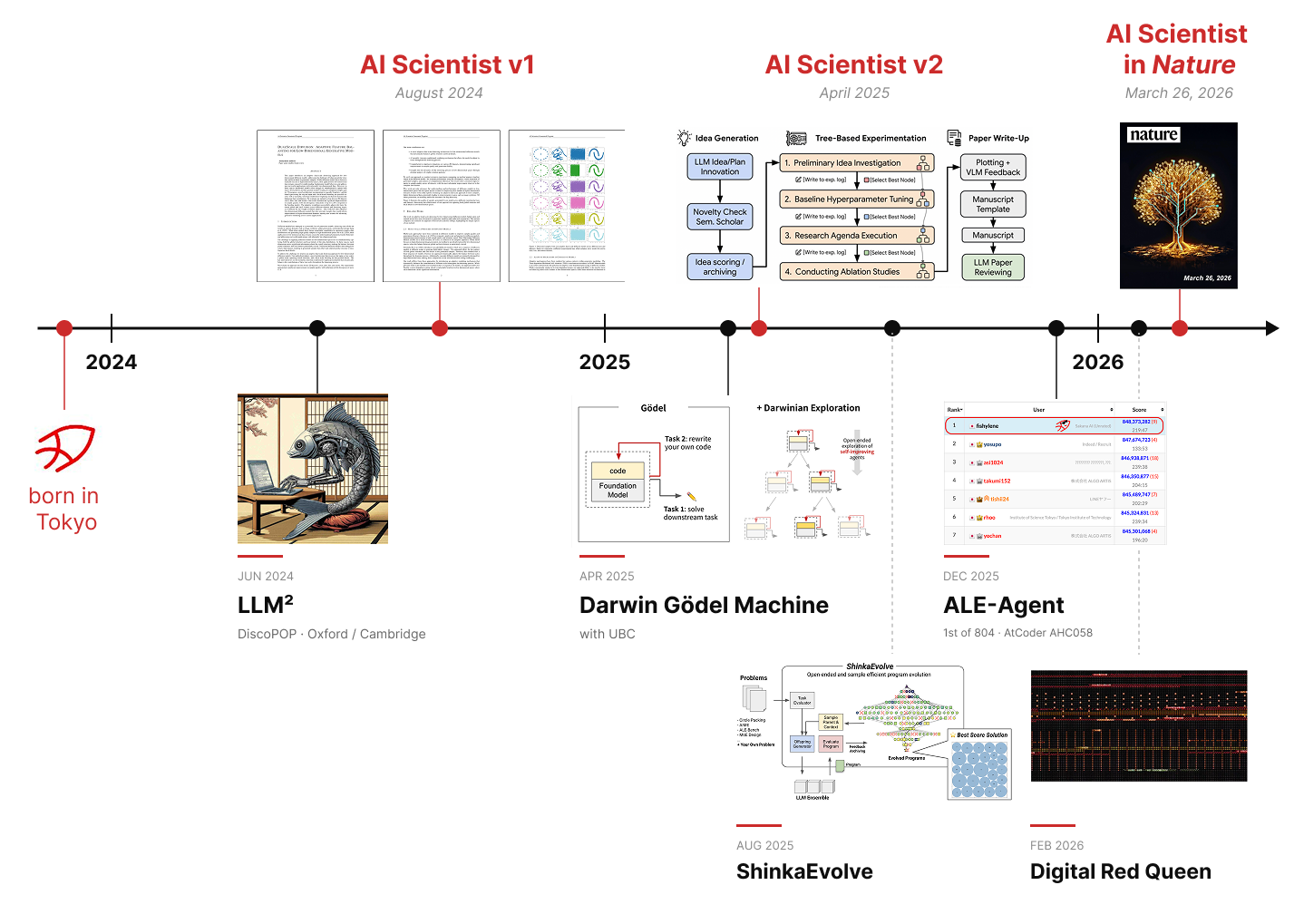 Sakana AIでのRSI研究の歩み
Sakana AIでのRSI研究の歩み
- LLM-Squared(2024年):オックスフォード大学・ケンブリッジ大学との共同研究。LLM自身に「LLMをより良く学習させる方法」を発明させることから、「LLM²」と名づけました。その成果が、選好最適化アルゴリズム「DiscoPOP」です。選好最適化とは、「二つの出力のうちどちらが望ましいか」という人間の比較データをもとにモデルを調整する手法のことで、DiscoPOPはこのアルゴリズムを、世代を重ねる進化の過程のなかでLLMがほぼ自力で発見・記述したものです。さらにこの研究は、AIが自身を改良するRSI(いわば「AI²」)構想の萌芽と呼べるものです。
- The Darwin Gödel Machine(2025年):ブリティッシュ・コロンビア大学(UBC)の研究者との共同研究です。DGMは、自らのコードを書き換えるエージェントを少しずつ変異・選択させながら系統樹のように増やしていくことで、途切れのない自己改善を実現します。実際のソフトウェアの不具合を修正できるかを測る標準的なベンチマーク「SWE-bench」では、出発点となる性能を自動的に2倍以上に引き上げ、絶対値で30ポイントの向上を達成しました。
- ShinkaEvolve(2025年):科学的発見のためのプログラム進化を、高いサンプル効率で行えることを示したオープンソースのフレームワークです。サンプル効率とは、答えにたどり着くまでに必要な試行回数の少なさを指します。ShinkaEvolveは、適応的サンプリングと新規性フィルタリングという工夫により、わずか150回の試行で複雑な最適化問題を解きました。さらに、複数の専門家モデルに処理を振り分けるMixture-of-Experts(MoE)の構造で、その振り分けの偏りを抑える新しい損失関数(ロードバランシング損失)まで自ら考え出しています。
- ALE-Agent(2025年):競技プログラミングの大会「AtCoder Heuristic Contest 058」で、804名の人間の参加者を抑えて1位を獲得した最適化エージェント。多くの計算を推論時に費やすだけでなく、自らの失敗から教訓を引き出して学ぶ仕組みを備えており、人間の専門家を上回るアルゴリズムを自力で導きました。
- Digital Red Queen(2026年):MITとの共同研究。「Core War」という、仮想の計算機上で自作プログラム同士を戦わせる古典的なプログラミングゲームを舞台に、終わりのない敵対的な共進化を再現しました。LLM同士が互いに競い合うコードを書くうちに、複雑なソフトウェア戦略がひとりでに立ち現れ、異なる系統が似た解にたどり着く「収斂進化」のような現象も観測されています。攻撃側と防御側が、脆弱性を見つけ、突き、ふさぎながら絶えず競い合うこの構図は、RSIをサイバーセキュリティへ応用するための足がかりになると考えています。
- The AI Scientist(2024〜2026年):アイデアの着想から、実験の実行、論文の執筆、査読まで、研究のひととおりの流れを自動でこなすシステム。2025年には、AIが完全に自動生成した論文がトップ会議のワークショップで査読を通過しました。この研究は2026年3月26日にNature誌へ掲載されました。
これらの研究の根底には、Sakana AIが創業当初から大切にしてきた一つの姿勢があります。「計算資源の量ではなく、アイデアで進歩する」という姿勢です。ShinkaEvolveは、しらみつぶしの探索では手に負えない問題を、わずか150回の試行で解きました。ALE-Agentは、推論にかける計算を増やすのではなく、自らの失敗から学ぶことで専門家を上回りました。RSIへの取り組みも、この信念のうえに立っています。私たちがめざすのは、最も多くの計算資源を注ぎ込む自己改善ではなく、最も少ない試行で前へ進む自己改善です。そして私たちは、その成果を、ごく一部の巨大な計算基盤に頼らず、現実的な規模の計算資源の上でこそ積み上げていきたいと考えています。
AIによるAI構築を通して、AIの民主化を実現する
私たちのより大きなビジョンは、これまでのAI開発が抱えてきた限界を超え、AIが自ら良くなり続ける軌道へと移っていくことです。この移行を、私たちは4つの段階として思い描いています。
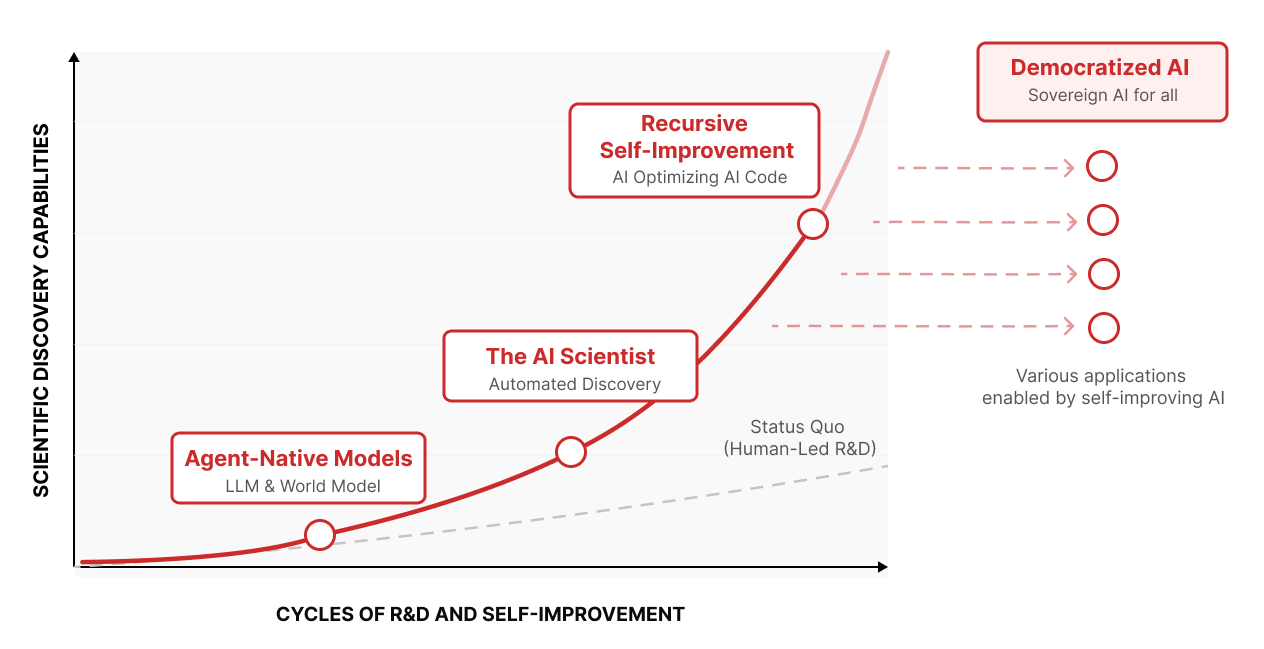 再帰的自己改善(RSI)へのロードマップ
再帰的自己改善(RSI)へのロードマップ
- エージェントネイティブモデル(Agent Native Model): 質問に答えるチャット用途を前提とするのではなく、はじめから、自ら考えて動くエージェントとしての用途を念頭に設計された土台のモデルです。世界の仕組みを内部でシミュレートする力を含め、その基礎を築きます。
- エージェント型サイエンティスト(The AI Scientist): こうしたモデルを実際に動かし、研究の最初から最後までを自動で進めさせることで、科学的な知識を自ら少しずつ広げていきます。
- 再帰的自己改善(Recursive Self-Improvement): AIが、自らの土台となるアーキテクチャのコードを自分で書き、性能を測り、検証するようになります。AIがAI自身を改良していく循環が動き出す、決定的な転換点です。
- AIの民主化(Democratized AI): 少ない試行で行える自己改善が実現すれば、フロンティアAIの風景が大きく変わります。これまで計算規模の差で太刀打ちできなかった国や組織、分野が、自分たちの課題に本当に必要なAIを、自分の手で作れるようになるからです。再帰的自己改善の実現を通して、AIの恩恵を勝者総取りではなく、社会全体で使える公共財に変えることができると考えています。
現在、フロンティアのAI研究は、巨大な計算資源を持つ一部の国でしか本格的に試みられていません。日本の計算資源は、世界的に見れば決して小さくないものの、巨大クラウド事業者(ハイパースケーラー)の規模には届きません。だからこそ、計算効率の高い自己改善は、日本のAI開発にとって避けて通れない前提になります。そして、この制約のもとで磨かれた技術は、ありあまる計算資源を前提とした技術よりも、かえって多くの場所で応用が利くものになるはずです。
私たちがRSI Labを東京で始動するのは、まさにこの理由からです。日本が力を入れるソブリンAI(自国で主体的に開発・運用するAI)の国家戦略は、制度の面から私たちを後押ししてくれます。そして、世界の計算資源の地図のなかで日本が置かれた現実的な立ち位置こそが、あえてその制約のもとで挑むことの意味を与えてくれるのです。
責任あるRSIに向けて
2年間こうしたシステムを作り続けてきて、私たちはその「壊れ方」を何度も間近で見てきました。学習が想定していた範囲から少しずつ外れていく進化のループ。ベンチマークの数字は良いのに、実際に使うとうまく働かない自己改変。与えたはずの制約をかいくぐる抜け道を見つけてしまうエージェント。これらは珍しい例外ではなく、再帰的自己改善という技術の中心にある、解くべきエンジニアリング課題だと受け止めています。
RSI Labの姿勢は、この認識から自然に導かれます。私たちは、うまくいかなかった結果も含めてオープンに公開していきます。そして、自己改善のループを、最初から検証可能な安全策とともに設計します。責任あるRSIは、性能の足かせではありません。むしろ、性能を長く伸ばし続けるための条件そのものだと考えています。

RSI Labのチームを立ち上げます
RSI Labは、計算知能の次の前進を、夢物語ではなく、解くべき工学の問題として引き受けるための組織です。私たちはこの目標に向けて、東京本社で専任の研究・エンジニアリングチームを立ち上げます。
このチームでは、とりわけ次の二つのポジションを中心にチームを構成します。
- RSIを切り拓くリサーチサイエンティスト: トップのフロンティアラボで実績を積み、標準的なベンチマーク競争の先へ踏み出そうとする研究者を招聘します。とりわけ、必要な計算量そのものを減らすような機械知能の新しい法則を探究する方、サイバーセキュリティ・自動レッドチーミングといった重要度の高い領域に、オープンエンドな進化の考え方を応用する方を迎えます。
- RSIを実装するソフトウェアエンジニア: 探索パイプラインを最適化し、大規模に分散した計算環境を扱い、自動でコードを生成する仕組みを実運用の規模で動かせるエンジニア、システム・インフラ・パフォーマンスの専門家を迎えます。
これらのポジションの公募については採用ページのMember of Technical Staff(RSI Lab)をご覧ください。
なお、Sakana AIでは、AIの研究開発と社会実装に関する幅広い職種で採用を行っています。当社でのキャリアにご関心のある方は、採用ページをご覧ください。