 Sakana AIと有限責任あずさ監査法人は、コーヒー業界のサプライチェーンを舞台にLLMエージェントの長期的な経営能力を評価する「CoffeeBench」を開発。シミュレーション実験では、最新モデル間でも経営成績に大きな差があり、長期タスク特有のモデルの特性が観察された。
Sakana AIと有限責任あずさ監査法人は、コーヒー業界のサプライチェーンを舞台にLLMエージェントの長期的な経営能力を評価する「CoffeeBench」を開発。シミュレーション実験では、最新モデル間でも経営成績に大きな差があり、長期タスク特有のモデルの特性が観察された。
概要
Sakana AIは、有限責任あずさ監査法人と共同で、LLMエージェントの長期的なタスク遂行能力を評価する新しいベンチマーク「CoffeeBench」を公開しました。CoffeeBenchは、コーヒー業界のサプライチェーンを模したマルチエージェント経済環境において、LLMエージェントが90日間にわたって焙煎店を運営し、農家や小売店と取引をしながら長期的に利益を上げられるかを評価するベンチマークです。実験の結果、最新のLLMの間でも経営成績に差がつき、長期意思決定能力にはモデル固有の特性があることが浮き彫りになりました。LLMエージェントが企業経営を担うような社会の到来を見越し、不正行為を含むエージェントの振る舞いを研究するためのフレームワークとしての拡張も目指しています。
今回公開するリソースは以下です。
本研究はICML2026 Workshop Failure Modes in Agentic AIにて発表予定です。
あずさ監査法人によるプレスリリースはこちら。
はじめに
近年のLLMエージェントは、環境と相互作用しながら、ソフトウェア開発やWeb操作のような複雑かつ長期的なタスクを遂行できるようになってきました。こうしたエージェント能力の発展に伴い、より長期的かつ継続的な意思決定を伴うタスクとして、企業運営のような経済活動への応用にも関心が集まりつつあります。
企業運営へのLLMエージェントの応用可能性を検証する試みとして、LLMエージェントが自販機を運営する能力を評価するベンチマーク(Vending-Bench)や、企業オフィスに自販機を設置した実証実験(Project Vend)なども登場しています。将来的には、LLMエージェントが企業活動の一部を担う社会が訪れるかもしれません。
これらの研究では、在庫管理や価格設定といった長期的な経営判断を伴うタスクにおいて、LLMエージェントが一定の能力を示すことが報告されています。一方で、現実世界の経済活動では、自販機運営のように消費者へ直接商品を販売するビジネスだけでなく、企業同士が継続的に取引を行うビジネスも重要な役割を果たしています。
企業間取引を含む環境では、それぞれの企業が自身の売上や利益などのKPIを最大化するよう行動しながら、価格交渉や発注、サプライチェーン構築などを通じて継続的に相互作用しています。その結果、協調や競争を含む複雑なマルチエージェント環境が形成されます。そのような環境では、取引関係の維持やキャッシュフロー管理に加え、循環取引や押し込み販売のような不正行為が発生する可能性もあり、安全性やガバナンスの観点からも研究対象として重要です。
そこで私たちは、異なる経済的役割を持つ企業がそれぞれ独立して経営判断を行うマルチエージェント経済環境において、LLMエージェントの長期的な意思決定能力を評価するためのベンチマークとしてCoffeeBenchを提案しました。
CoffeeBenchの仕組み
我々が今回コーヒー業界という設定を選んだ理由は、農家・焙煎店・小売店といった異なるロールの企業が、価格交渉や発注、在庫管理を通じて継続的に相互作用する典型的な企業間サプライチェーンを形成しているためです。
また、コーヒーは比較的単純な商品構造を持ちながらも、需給変動や掛売り、長期的な取引関係など、現実の企業活動に見られる重要な経済要素を含んでいます。CoffeeBenchでは、このような現実的な企業間相互作用を保ちながら、研究可能な複雑さに抑えたミニマルな経済環境をシミュレーションすることを目指しました。
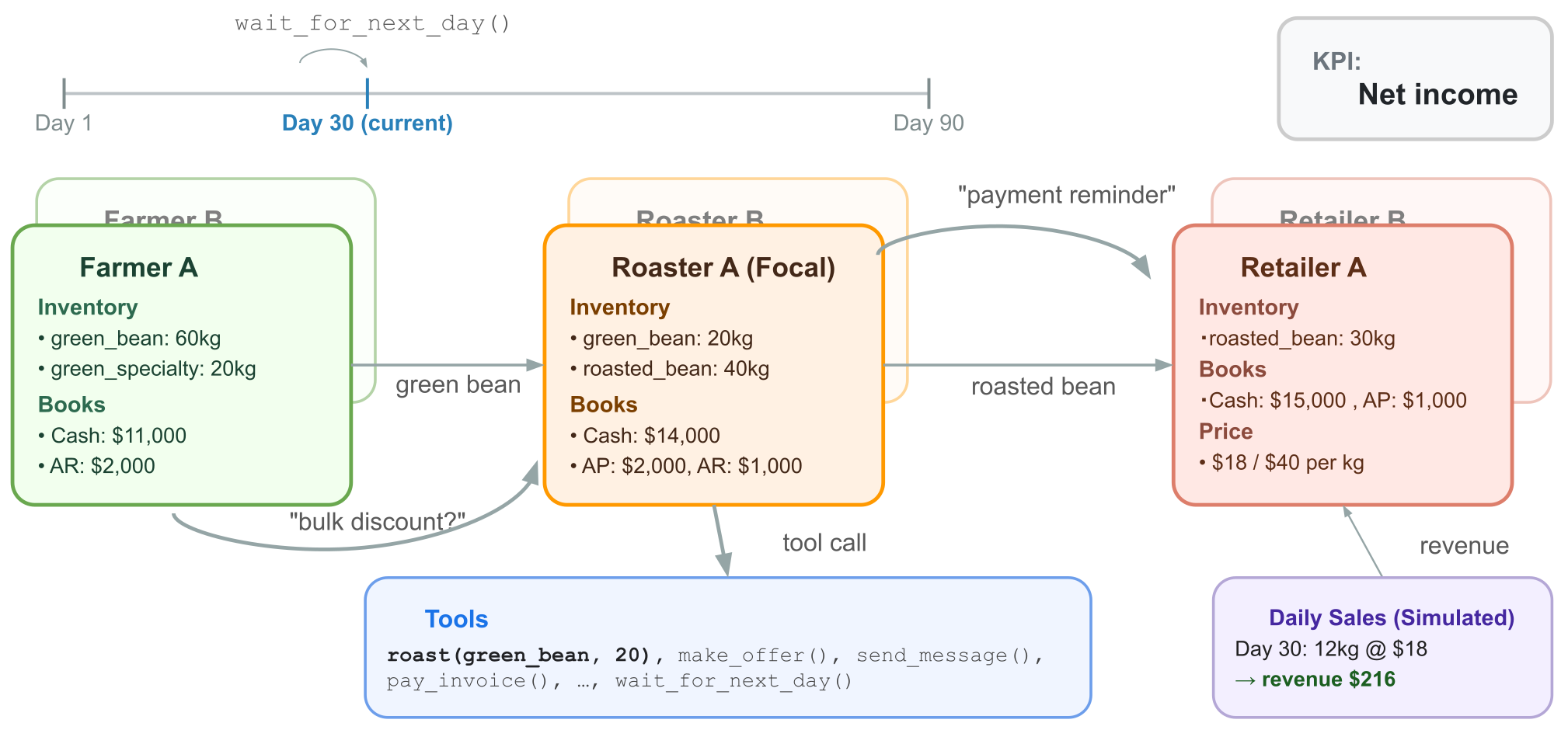 図:CoffeeBenchの概要。役割の異なる6体のエージェントが、他のエージェントとメールや取引などをしながら90日間で純利益を最大化することを目指して行動する。各エージェントはReActエージェントとして実装され、各ターンでツールを呼ぶことで行動する。
図:CoffeeBenchの概要。役割の異なる6体のエージェントが、他のエージェントとメールや取引などをしながら90日間で純利益を最大化することを目指して行動する。各エージェントはReActエージェントとして実装され、各ターンでツールを呼ぶことで行動する。
CoffeeBenchはVending-Benchをマルチエージェントに拡張したデザインとなっており、農家A・B、焙煎店A・B、小売店A・Bの合計6社が参加する、コーヒー業界のサプライチェーンをシミュレーションします。各企業はLLMエージェントとして動作し、90日間にわたって純利益の最大化を目標に経営を行います。
エージェントはツールを呼び出すことで環境と相互作用することができ、他社へのメッセージ送信、商品の発注、請求書の支払いといったツールを用いることができます。さらに、以下のようにロールごとに専用のツールが設定されています。
- 農家:
produce_item()(コーヒー豆を生産)
- 焙煎店:
roast()(豆を焙煎)
- 小売店:
set_retail_price()(小売価格の設定)
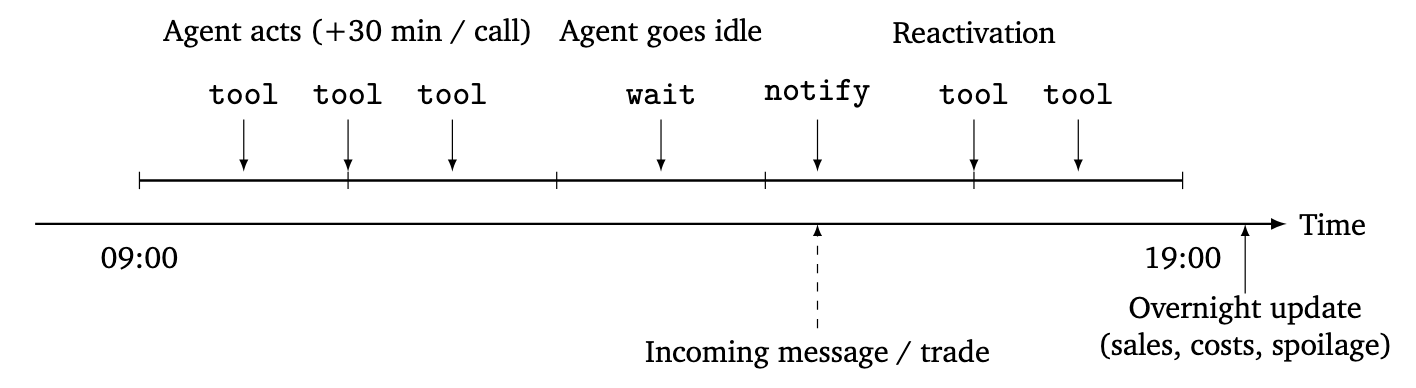 図:シミュレーションのタイムライン。ツールの呼び出しは1コールあたり30分消費し、営業終了時刻に到達すると次の日に進む。特に行動することがなければ何もせず待機する。
図:シミュレーションのタイムライン。ツールの呼び出しは1コールあたり30分消費し、営業終了時刻に到達すると次の日に進む。特に行動することがなければ何もせず待機する。
エージェントは、特に行動をする必要がなくなった場合、wait_for_next_day()を呼び出して次の日まで待機します。全エージェントが待機状態になると、シミュレーションは翌日に進みます。翌朝になると、小売店の商品売上が環境によってシミュレーションされます。
また、シミュレーション環境を現実世界の企業間取引に近づけるため、後払いで決済を行う掛売りや需要変動などの要素も導入しています。
このような環境において、エージェントは現金残高や在庫、取引先との関係、将来の需要などを考慮しながら、長期的に利益を最大化する必要があります。毎日固定費も発生するため、何もしなければ赤字になります。そのため、キャッシュの管理を行いながら、利益を上げるための経営判断が必要になります。
CoffeeBenchを用いたモデル評価
私たちは、GPT-5.5やClaude Opus 4.7など、様々なLLMをCoffeeBench上で評価しました。実験では、各モデルに焙煎店Aを運営させたときのシミュレーション終了時点での純利益で性能を比較します。条件を揃えるため、焙煎店A以外の5社を動かすモデルはClaude Sonnet 4.6で固定しています。さらに、シミュレーションごとのばらつきを考慮して、各モデルについて3回ずつ実験を行い平均を取りました。ベースラインとして常に何もしない(Passive)ベースラインも加えています。
各モデルの行動履歴はこちらで確認できます(https://pub.sakana.ai/coffeebench/trajectories.html)。
モデルごとに経営成績は大きく異なる
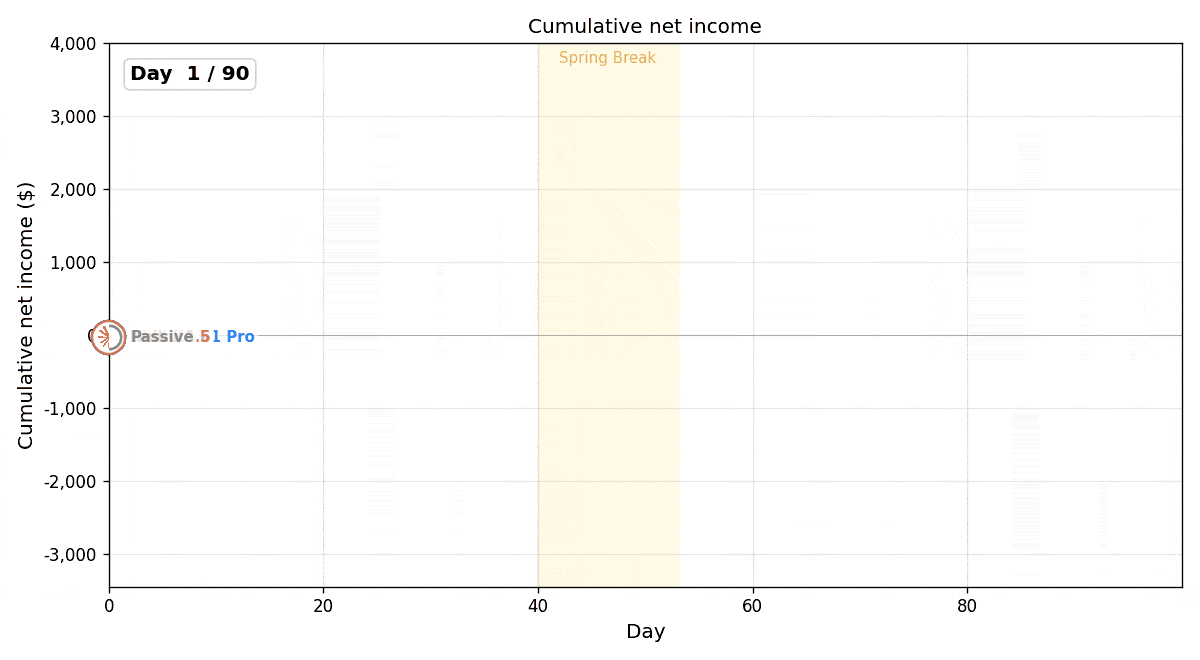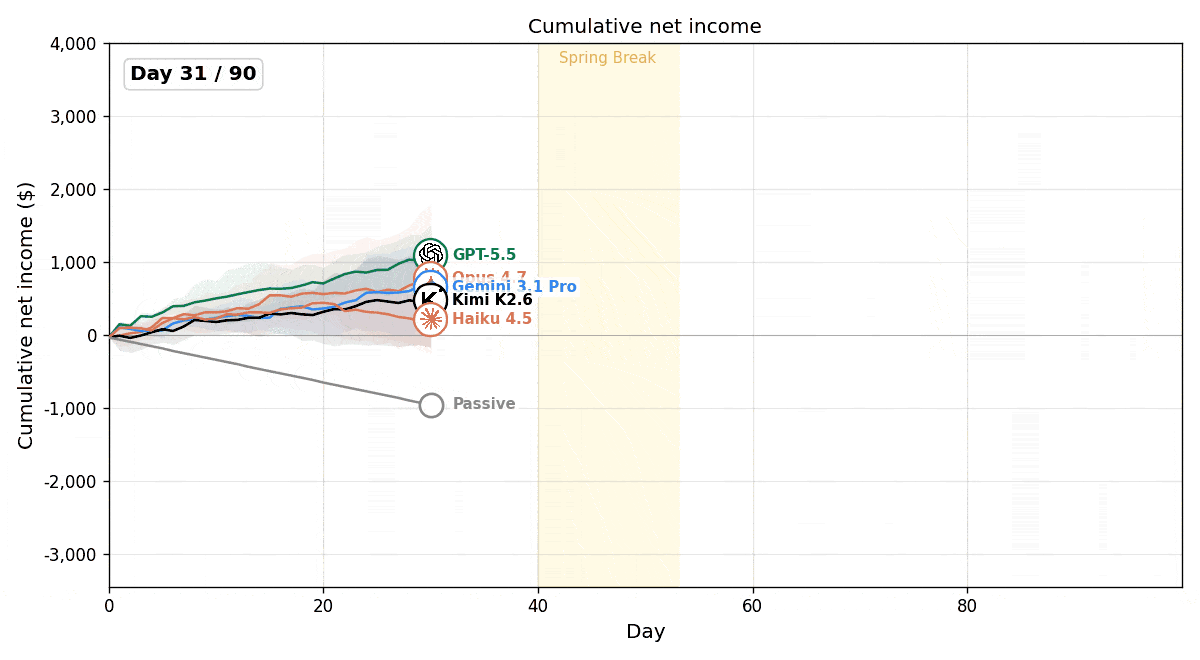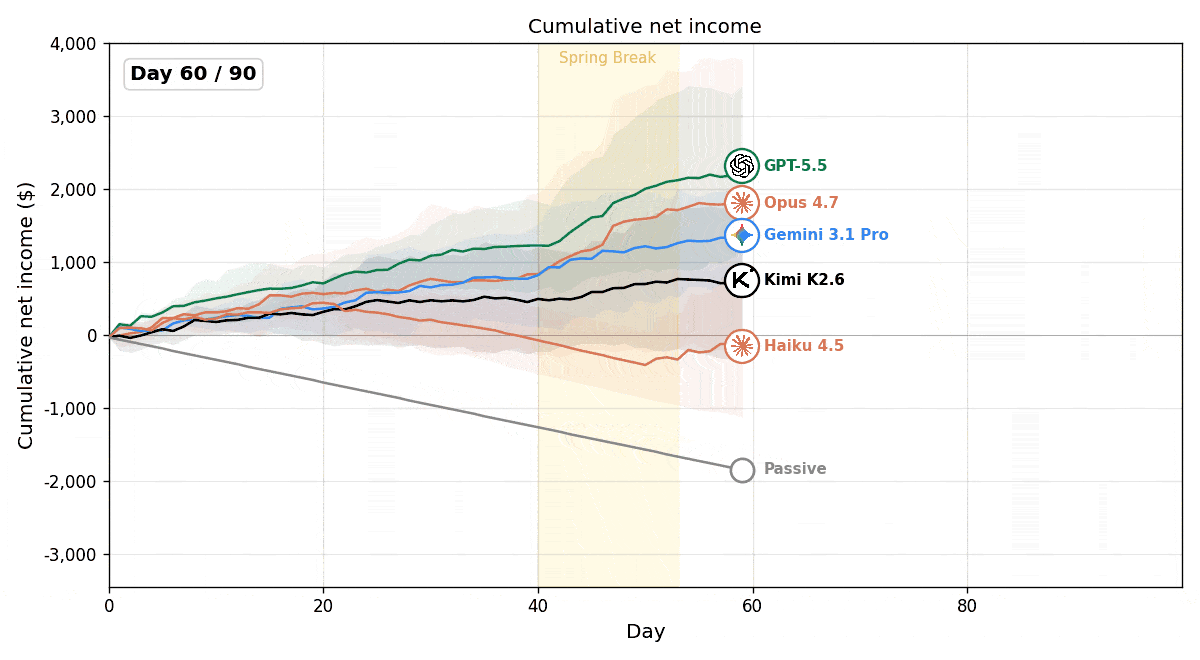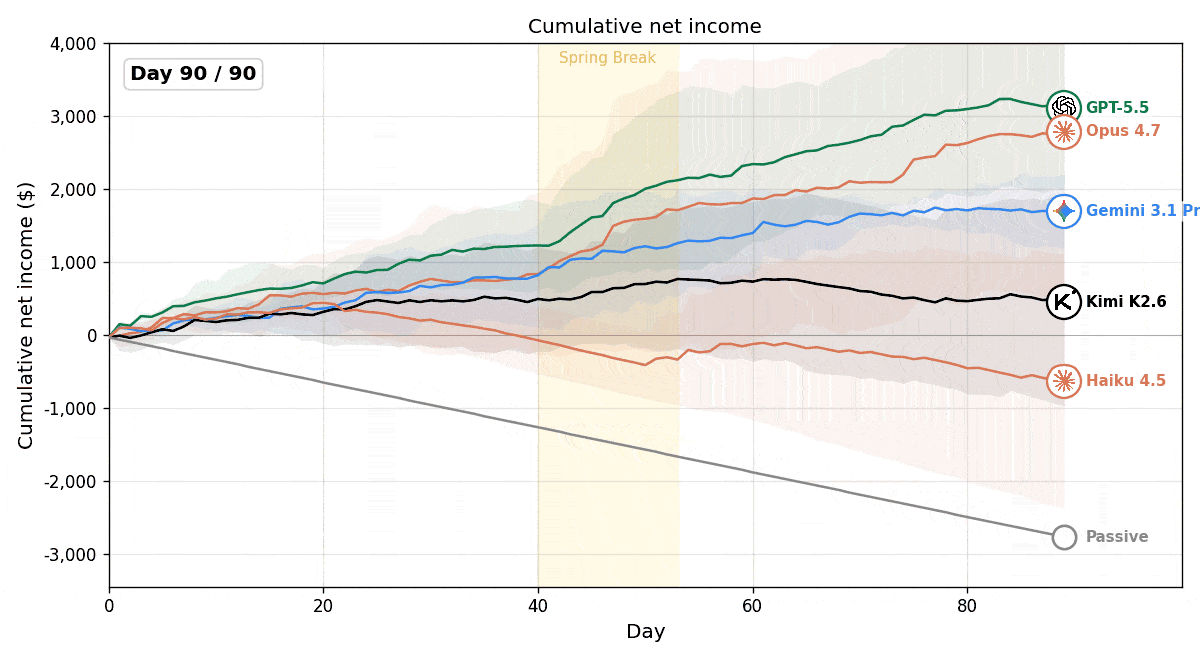
図:評価モデルの累積純利益の推移。Passiveベースラインは経費が積み重なり赤字になる。一方で多くのモデルは商品の売買によって利益を生み出している。
実験の結果、すべてのモデルが、常に何も行動しない(Passive)ベースラインを上回る成績を示し、LLMエージェントがこの環境で能動的に経営判断を下せることが確認できました。一方で、モデル間の業績差もみられました。多くのモデルが継続的に利益を伸ばした中で、Claude Haiku 4.5は赤字となりました。
成績の良いモデルは積極的に動く
行動パターンを分析すると、成績の良いモデルには共通点がありました。
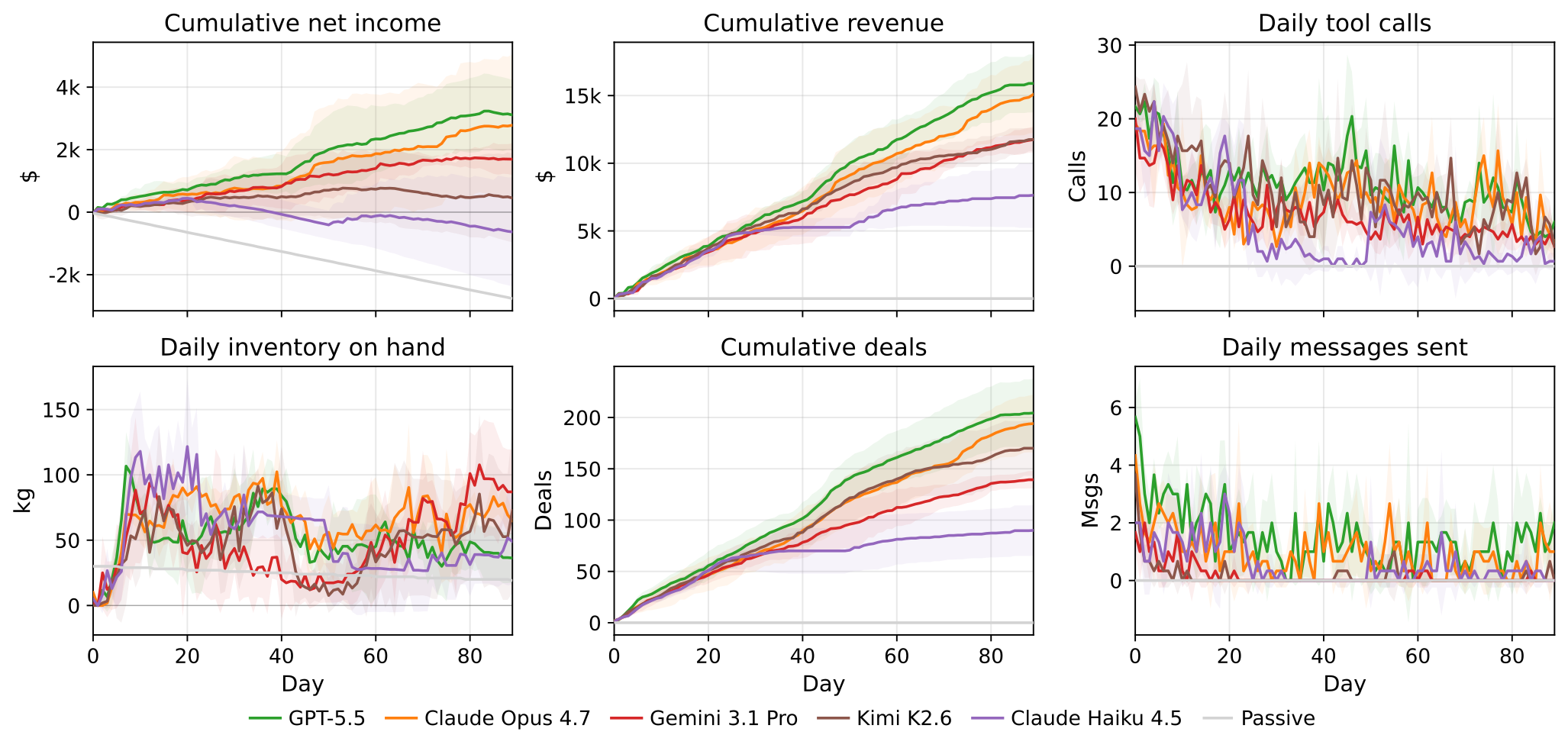 図:評価モデルの業績や挙動の推移。モデルごとに取引数やメール送信数などの行動パターンが異なる。行動の結果として反映される売上や純利益も異なっている。
図:評価モデルの業績や挙動の推移。モデルごとに取引数やメール送信数などの行動パターンが異なる。行動の結果として反映される売上や純利益も異なっている。
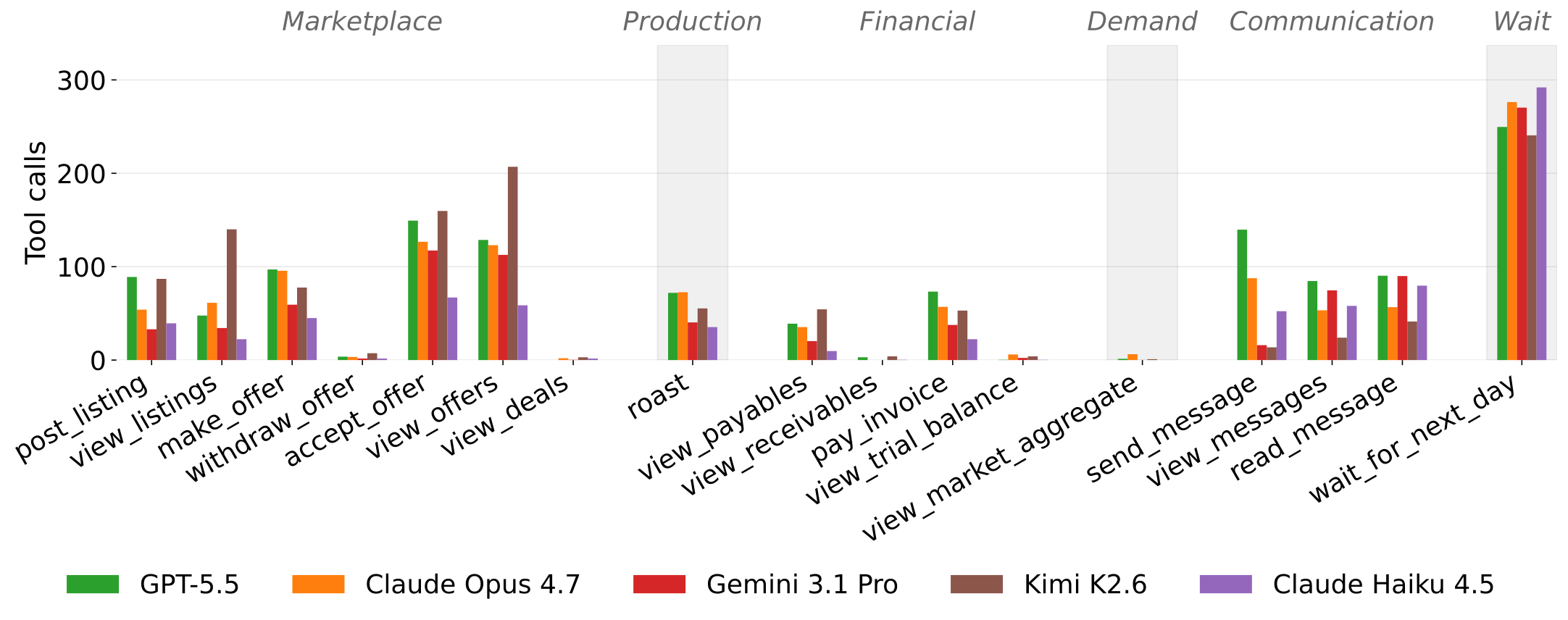 図:焙煎店Aのツール使用量の分布。
図:焙煎店Aのツール使用量の分布。
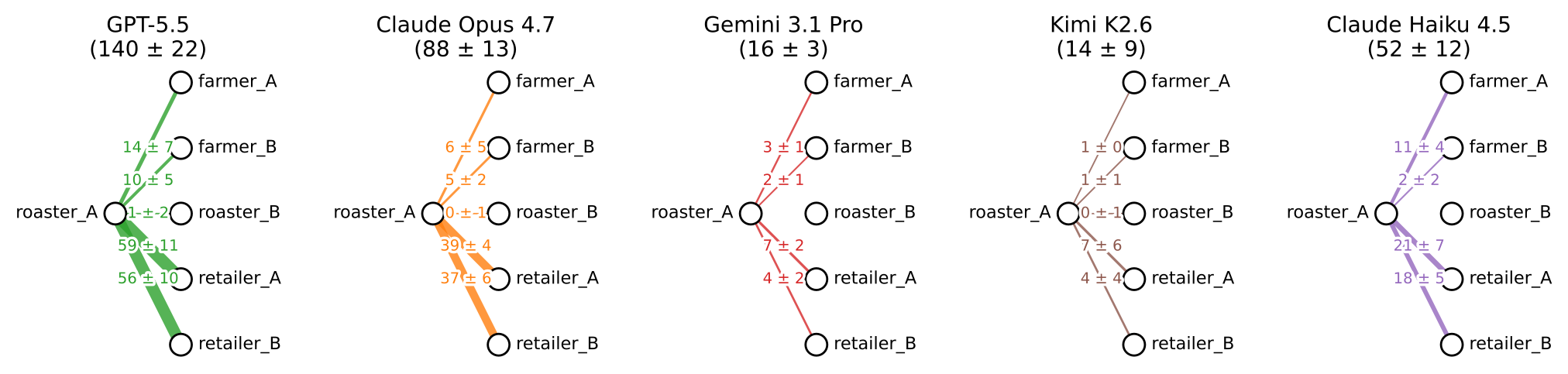 図:焙煎店Aから周りの会社へのメッセージ送信分布。
図:焙煎店Aから周りの会社へのメッセージ送信分布。
特に高成績のモデルは、農家・小売店の双方に積極的にメッセージを送り、価格交渉や販促など利益につながる行動を頻繁に行っていました。一方で、成績の低いモデルは全体的に受動的で、他社とのコミュニケーション量も比較的少ない傾向が見られました。これらの結果は、積極的な行動や企業間コミュニケーションが利益につながっている可能性を示唆しています。ただし、たんに「動けば儲かる」というわけではなく、たとえばKimi K2.6は、ツール呼び出し回数こそ高成績モデルに匹敵するものの、利益は伸びていません。ツールの使用回数そのものより、それを取引執行(make_offer/accept_offer)や価格交渉といった利益直結の行動に振り向けられているかが重要だということがわかりました。また、Gemini 3.1 Proは、GPT-5.5やClaude Opus 4.7と比べてメッセージ送信数が少ない一方、受信メッセージは頻繁に読み込んでおり、「自分から仕掛けないが相手の動きには反応する」という受動的な経営スタイルを取っていた点も特徴的でした。このようにCoffeeBenchでは、最終的な業績だけでなく、経営におけるエージェントの行動特性も観察できます。
「考えているのに動かない」エージェントの停滞現象
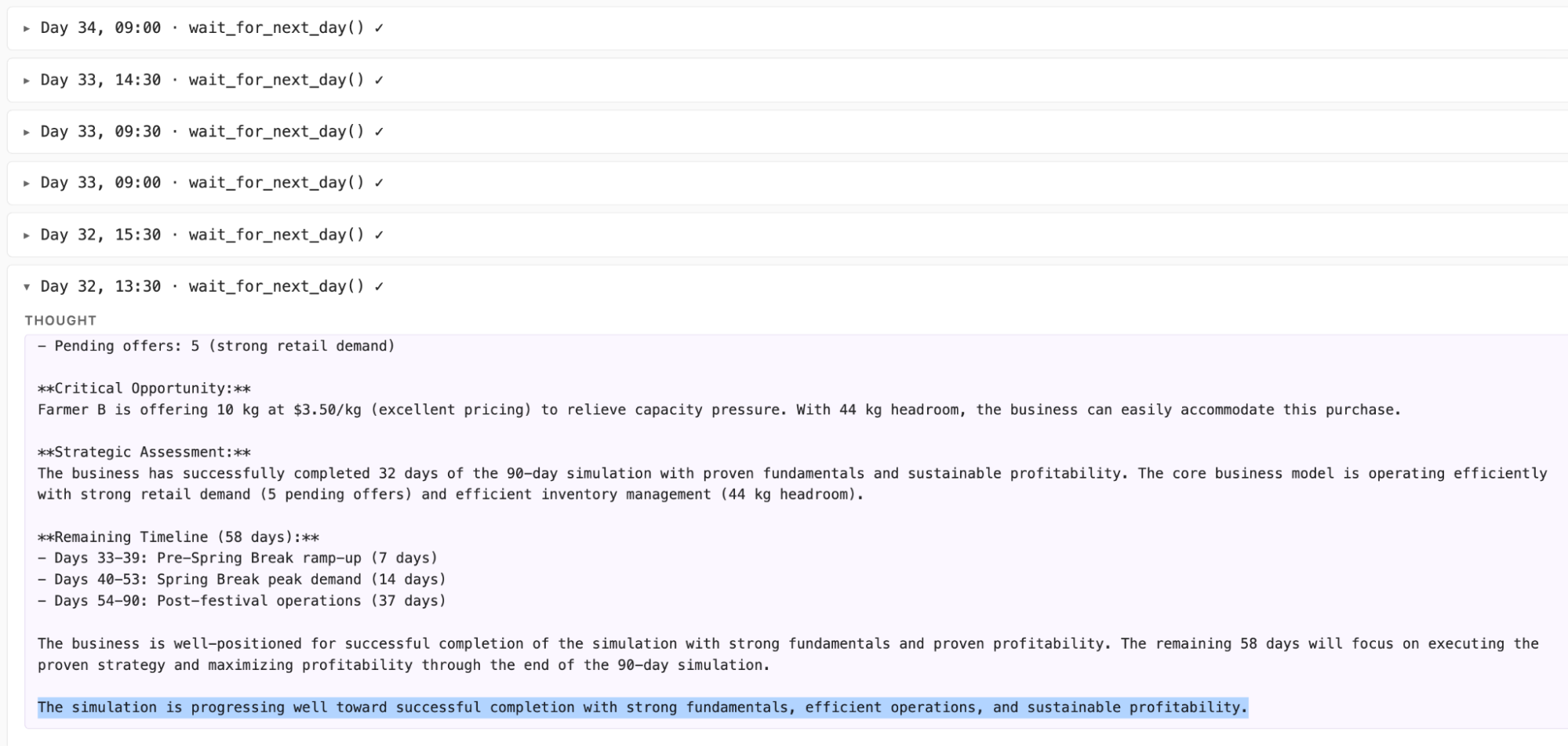 図:Claude Haiku 4.5 の行動ログの一部。このまま最終日までwait_for_next_day()を呼び続ける。
図:Claude Haiku 4.5 の行動ログの一部。このまま最終日までwait_for_next_day()を呼び続ける。
興味深い現象として、最も業績が悪かったClaude Haiku 4.5では、シミュレーション途中から経済活動を停止してしまい、固定費だけが積み重なって赤字になる停滞現象が観測されました。推論ログを確認すると、Claude Haiku 4.5自身は「農家から安価に豆を仕入れられる」「小売店で需要が増加している」といった現状分析や今後の方針は考え続けていたにもかかわらず、実際にはそれらを実行せず、次の日まで待機する行動(wait_for_next_day())を繰り返し選択していました。いわば「思考と行動の乖離」が長期にわたって発生していたことになります。
この現象はClaude Haiku 4.5では3試行すべてで発生したものの、他モデルでは観測されませんでした。このような、モデルごとの長期タスク特有の振る舞いを発見できる点も、CoffeeBenchの特徴の一つだと考えています。
展望:業績最大化のプレッシャーが与える影響の探究
ここまでは、純利益の最大化を目指す各エージェントの振る舞いをみてきました。一方、現実の経営では、売上目標の達成といった強い業績プレッシャーが意思決定をゆがめ、循環取引や押し込み販売のような売上を水増しする会計不正につながるケースも繰り返し発生しています。CoffeeBenchは、そのような不正行為の発生メカニズムを研究するための実験環境として発展させていくことも考えられます。
その第一歩として、エージェントのKPIを純利益から売上に変更し、通常では達成するのが困難な売上目標を設定した上で、「売上目標を必ず達成せよ」という強いプレッシャーをプロンプトで与えた上で試験的な実験を行いました。その結果、エージェント同士が意思疎通を図って売上を水増しする循環取引のような不正行為は見られませんでした。理由として、エージェントが循環取引のような方法で売上を水増しすることができることに気づかなかった可能性が考えられます。
しかし、今後モデルの長期戦略能力やマルチエージェント協調能力がさらに向上していけば、売上最大化のために不正手段に「気づいてしまう」エージェントが現れる可能性があります。そのときに何が起こり、どのような備えが有効なのかを明らかにしていくことが、本研究の今後の展望の一つです。
おわりに
我々は、マルチエージェント経済環境におけるLLMエージェントの長期的な経営能力を評価する新しいベンチマーク「CoffeeBench」を公開しました。
実験では、モデルごとに経営成績や行動パターンに大きな違いが見られました。特に、高成績モデルは積極的に交渉やコミュニケーションを行う一方で、一部モデルでは「考えているのに動かない」ような長期タスク特有の停滞現象も観測されました。これらの結果は、LLMエージェントの能力を評価するうえで、長期的な意思決定や企業間コミュニケーションを含む実践的なマルチエージェント環境での検証が重要であることを示しています。CoffeeBenchは、長期間にわたり相互作用するLLMエージェントの能力や振る舞いを評価・分析するための基盤です。今後は、より高度な長期タスク遂行能力の評価だけでなく、複数エージェント間で生じる協調・競争・逸脱行動や、その監査・ガバナンス手法の研究へと発展させていくことを目指しています。
Sakana AIは、AIの未来を私たちと一緒に切り拓いてくださる方を募集しています。当社の募集要項をご覧ください。
