Sakana AI Releases ‘Fugu Ultra’ to Match Frontier Performance via Autonomous Model Orchestration.
Our Fugu Ultra model stands shoulder-to-shoulder with leading models like Anthropic’s Fable 5 and Mythos Preview across the industry’s most rigorous engineering, scientific, and reasoning benchmarks while delivering frontier capability without the risk of export controls.
(*日本語は英文の後に)
We are excited to introduce Sakana Fugu, a new product from Sakana AI that delivers a full multi-agent orchestration system as a single foundation model. Fugu dynamically orchestrates the world’s best models to tackle complex, multi-step tasks, accessible through a single model API. The result is multi-agent intelligence delivering the very best frontier-level performance without any single-vendor dependency or the complexity of a traditional multi-agent system.
👉 Sakana Fugu

Sakana Fugu is itself a language model trained to call various LLMs in an agent pool, including instances of itself recursively. Fugu dynamically orchestrates the world’s best models to tackle complex, multi-step tasks. Plug collective intelligence directly into your workflows today with a single API.
Beyond Bigger Models: Orchestration Models are the Next Frontier
For the past few years, progress in AI has been driven largely by brute-force scale: building giant, monolithic models trained on ever-larger amounts of data. But hard, real-world tasks require a multitude of specialized knowledge and skills, far beyond any individual benchmark. Unlocking the very best performance therefore requires collective intelligence: knowing which model to use, delegating tasks such as planning and execution, and combining domain-specific strengths while routing around individual weaknesses.
Since our founding, Sakana AI has been guided by a core conviction: the most powerful AI systems will not be isolated monoliths, but collaborative ecosystems. Evolution innovates under constraints, and the future belongs to systems that explicitly learn how to coordinate collective intelligence.
Today, this orchestration is no longer just a technical optimization; it has become a geopolitical and operational imperative. Recent disruptions in the AI landscape have demonstrated the severe risk of single-vendor dependency. For an organization or a nation, relying on a single company’s APIs for critical infrastructure, finance, or governance is a material vulnerability. This risk is no longer a hypothetical possibility, but a reality. As we have seen recently from export controls imposed on Anthropic’s Fable and Mythos models, access can shift or disappear overnight due to changing regulatory boundaries, export controls, and foreign policies.
Collective intelligence serves as the practical hedge against this concentration of power. Sakana Fugu is powered by models trained to be powerful orchestrators with an underlying pool of entirely swappable agents. If a single provider restricts access, Fugu dynamically routes around the disruption. Over time, Sakana Fugu will naturally grow by incorporating newer, more efficient models, including our own. By orchestrating the world’s models, we are delivering the realistic, resilient blueprint required for AI sovereignty.
What Is Sakana Fugu?
Sakana Fugu is a multi-agent system that behaves like a single model. You send a request to one endpoint, and Fugu decides how to handle it: solving it directly when that is enough, or assembling and coordinating a team of expert models when a task calls for more. It manages model selection, delegation, verification, and synthesis internally, so the complexity of a multi-agent system never reaches your code.
What makes this possible at scale is that Fugu is itself a language model specialized to understand when to delegate, how agents should communicate, and how to combine their work into a single, reliable answer. This approach builds on our research on learned model orchestration, including our recent ICLR 2026 papers Trinity and the Conductor. From the outside, you simply call one model. On the inside, a coordinated system of experts is doing the work.
Fugu and Fugu Ultra
At launch, Sakana Fugu comes in two models, so you can match the system to your workload. Both models can be accessed via a single OpenAI-compatible API.
Fugu balances strong performance with low latency, making it a great default for everyday work. It fits naturally into tools like Codex for coding and code review, as well as chatbots and other interactive services. For teams with data, privacy, or compliance requirements, Fugu also lets you opt specific agents out of its pool.
Fugu Ultra is tuned for maximum answer quality on hard, multi-step problems, coordinating a deeper pool of expert agents when accuracy and depth matter most. Early users have relied on it for demanding work such as AI research, paper reproduction, cybersecurity analysis, and literature and patent investigations.
Here is how the two models perform across standard benchmarks:
Our Fugu Ultra model stands shoulder-to-shoulder with leading models like Fable 5 and Mythos Preview across the industry’s most rigorous engineering, scientific, and reasoning benchmarks. It delivers frontier capability without the risk of export controls.
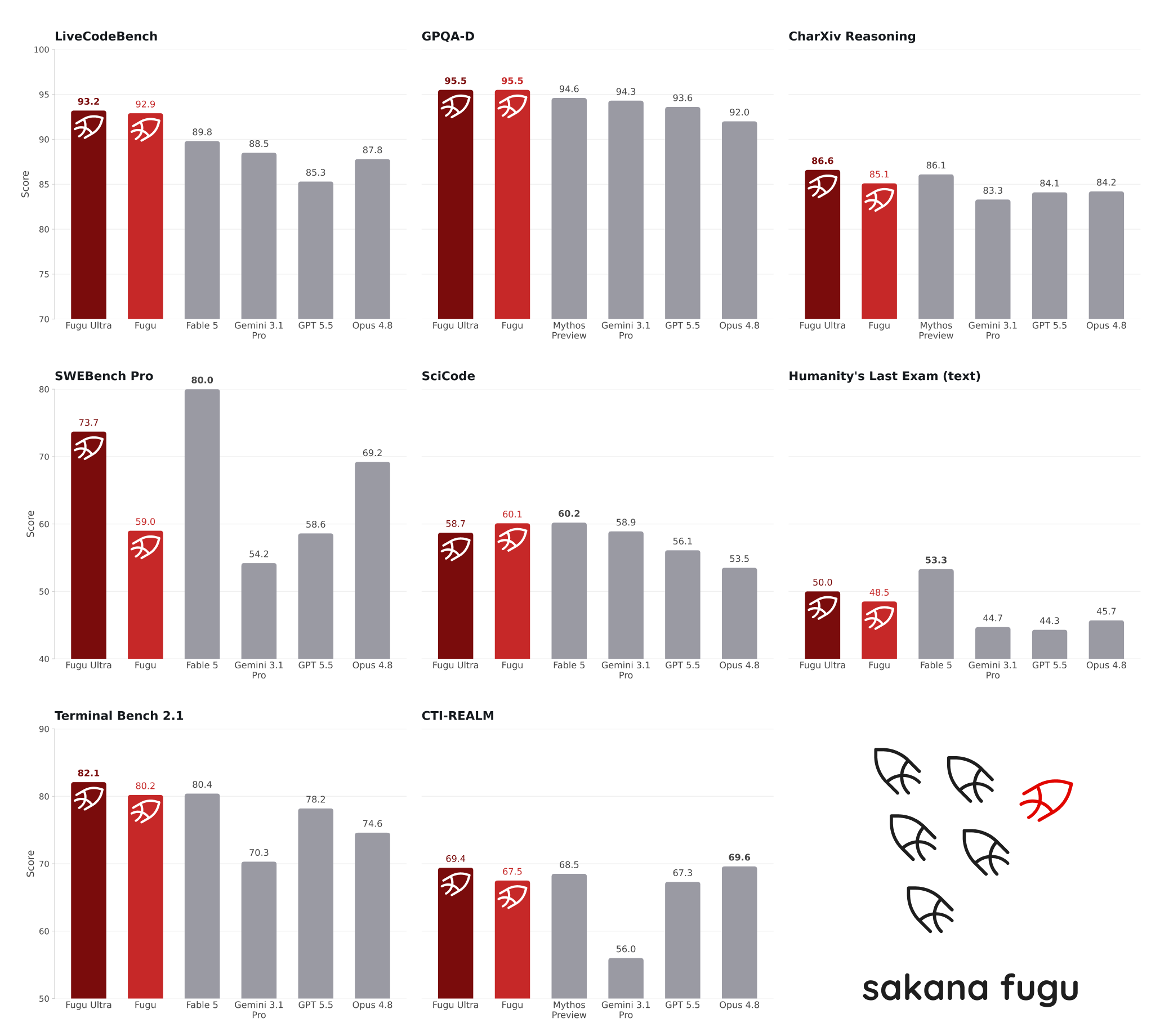
Performance comparison of Fugu models and baseline frontier models across a suite of coding, reasoning, scientific, and agentic benchmarks. All scores other than Fugu’s are reported by the model providers. For Fable 5 and Mythos Preview, we report the max of the two if both scores are available on the same benchmark. Neither of them is in Fugu’s agent pool as they are not publicly accessible. For more details, please refer to our technical report.
Benchmark results comparing Fugu with underlying foundation models used by Fugu, where highest scores are in boldface and the second highest are underlined:
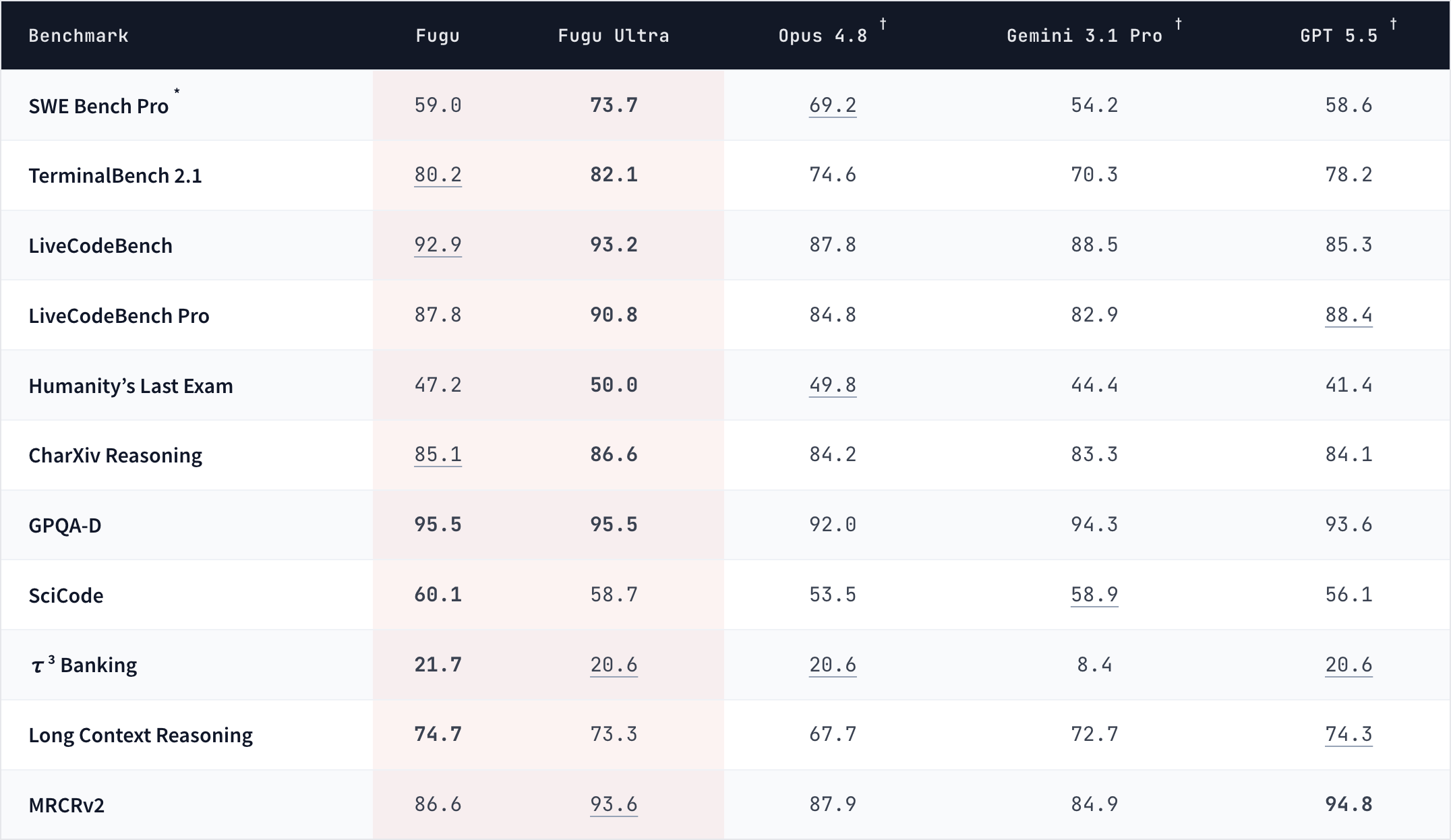
*We use the mini-swe-agent as the scaffolding for this task.
†We use model provider-reported scores for the baselines.
What Early Users Are Building
Benchmarks tell only part of the story. Fugu’s value shows up most clearly in long, messy, real-world workflows, which is exactly what we focused on during our beta program with close to 500 early users, whose feedback helped us improve the system.
Applications of Fugu Models. In our experiments, we find that Fugu Models consistently outperform frontier models Gemini 3.1 Pro (high), Opus 4.8 (max), and GPT 5.5 (xhigh) for various applications, such as AutoResearch, Rubik’s Cube, Mechanical Design, Japanese Handwriting Analysis, One-Shot Chess, Financial Time Series Prediction.
One of the clearest signals came from automated data science research: early users running Sakana Fugu in an almost fully automated research mode saw it drive meaningful progress with little to no human intervention. For us, this is exactly the kind of task Fugu Ultra is designed for: open-ended, multi-step work where the system needs to explore ideas, run experiments, interpret failures, revise its approach, and keep making progress over time.
Here is what other users are saying:
“For code review, Fugu Ultra is significantly better than GPT-5.5. It gives comprehensive answers and finds the bugs others miss. Where other tools flag about three issues, Fugu surfaced more than twenty. It's become the model I run all my reviews through.”
— Software Engineer, on Coding and Code Review
“Raw output quality is on par with top frontier models, but Fugu showed unusually strong persona stability across long sessions, holding its identity where other models drift. For agent products, that may matter more than raw benchmark scores.
— Executive at Enterprise Platform Company, on Orchestration Quality
“Given one scoped instruction, Fugu drove a full security assessment end-to-end — recon, XSS/SQLi checks, auth review, and a clean report with evidence and retest steps — staying inside scope and avoiding destructive actions.”
— Cyber Security Engineer, on Security Assessment Analysis
We saw similar patterns across paper reproduction, cybersecurity analysis, code review, and literature and patent investigations. In these workflows, the value of Fugu is not just a better answer to one prompt, but sustained progress across many steps: reading, implementing, testing, comparing evidence, finding gaps, and producing a useful final analysis or report. The beta made clear that multi-agent orchestration matters most when the task is messy, long-running, and difficult to solve with a single model call.
Sakana Fugu is generally available today. You can access both Fugu and Fugu Ultra through a single API, with subscription tiers for everyday use and a pay-as-you-go plan for heavier and enterprise workloads. To get started, visit our product page or console site.
Looking Ahead
We are deeply grateful to our early users who put Fugu through real, demanding work and helped us shape what it is today. This launch is a starting point, not a finish line. Because Fugu is built on learned orchestration rather than fixed workflows, it improves as the underlying ecosystem improves: as new frontier models arrive, we can fold them into Fugu’s agent pool and pass the gains on to you. In the months ahead, we plan to expand the pool of expert agents, including open models and Sakana AI’s own models, to strengthen coordination for long-running and agentic tasks, and give users more control over how Fugu works on their behalf. We are excited to see what you build with it.
We are looking for people to help shape the future of AI together with Sakana AI. Please see our careers page.
Publications
Sakana Fugu Technical Report, Fugu Team, Sakana AI, 2026.
Xu, Sun, Schwendeman, Nielsen, Cetin, Tang. TRINITY: An Evolved LLM Coordinator. ICLR 2026.
https://arxiv.org/abs/2512.04695
Nielsen, Cetin, Schwendeman, Sun, Xu, Tang. Learning to Orchestrate Agents in Natural Language with the Conductor. ICLR 2026.
https://arxiv.org/abs/2512.04388
Japanese
Sakana Fugu:マルチエージェントシステムを、一つのモデルAPIとして提供
Sakana AI、自律的なモデルオーケストレーションでフロンティア性能に並ぶ「Fugu Ultra」を提供開始
Fugu Ultraは、エンジニアリング・科学・推論といった業界屈指の厳しいベンチマークにおいて、AnthropicのFable 5やMythos Previewといった最先端モデルに比肩します。しかも輸出規制のリスクを負うことなく、フロンティアレベルの能力を発揮します。
Sakana AIは、マルチエージェントのオーケストレーションシステムを一つの基盤モデルとして提供する新プロダクト「Sakana Fugu(サカナ・フグ)」の提供を開始します。Sakana Fuguは、最高性能のモデル群を動的にオーケストレーションして複雑で多段階のタスクに取り組むシステムであり、単一のモデルAPIから利用できます。これにより、一つのベンダーに依存することなく、また自身で複雑なそうしたシステムをつくることなく、フロンティアレベルの性能を備えたマルチエージェントの能力を利用できます。
👉 Sakana Fugu
Sakana Fugu自体が一つの言語モデルであり、エージェントプール内のさまざまなLLMを呼び出すように学習されている。そこでは自分自身を再帰的に呼び出すこともある。Sakana Fuguは、最高性能のモデル群を動的にオーケストレーションし、複雑で多段階のタスクに取り組むことで、その集合知を一つのAPIですぐにワークフローに組み込むことを可能にする。
スケーリングの先へ:次のフロンティアとしてのオーケストレーションモデル
この数年、AIの進歩は主にスケールの追求、すなわち巨大で一枚岩のモデルをますます大量のデータで学習させることによって牽引されてきました。しかし、現実世界の難しいタスクでは、単一のモデルを一度呼び出すだけで最良の結果が得られることはほとんどありません。どのモデルを使うか、いつ処理を委譲するか、途中の作業をどう検証するか、そして個々のモデルの弱点を避けつつ、それぞれの強みをどう組み合わせるか。AIの最先端の能力は、こうした複数モデルの集合知をいかに活用するかに関する判断の積み重ねによって引き出されます。
Sakana AIは創業以来、たった一つ大きなモデルではなく、複数のモデルが協調するエコシステムをつくることで最も強力なAIシステムが実現できるという考え方を大切にしてきました。生物進化が様々な制約のもとで新たな解を見つけてきたように、集合知をどう協調させるかを自ら学習するシステムがこれからは重要になると考えています。
こうしたオーケストレーションは、技術的に理にかなったアプローチであるだけではなく、いまや地政学的にも、実務面でも、避けて通れない技術になっています。近年のAIをめぐる動向は、単一ベンダーへの依存が抱える深刻なリスクを浮き彫りにしました。組織にとっても国家にとっても、重要インフラや金融、行政を一社のAPIに頼って動かすことは、現実的な弱点になり得ます。そしてこのリスクは、もはや仮定の話ではなくなっています。最近のAnthropicのFable 5およびMythos 5モデルに課された輸出規制に見られたように、規制の枠組みや輸出管理、各国の政策が変われば、アクセスの条件は一夜にして変わり得ます。
集合知によるアプローチは、このような特定のプレイヤーへの集中に対する、現実的な備えにもなります。Sakana Fuguはオーケストレーションのためのモデルとして学習させたものであり、その背後で用いるモデル群は、必要に応じて柔軟に入れ替え可能です。仮にあるプロバイダーが利用を制限しても、Sakana Fuguはその影響を動的に迂回します。今後は、より新しいモデルや、Sakana AI自身のモデル、その他のオープンモデルも、随時プールに加えたり、入れ替えたりしていく予定です。世界中のモデルをオーケストレーションすることで、AI主権(AI sovereignty)を支える、現実的で確かな選択肢を示していきたいと考えています。
Sakana Fuguとは
Sakana Fuguは、単一のモデルのように振る舞うマルチエージェントシステムです。ユーザーが一つのエンドポイントにリクエストを送ると、Sakana Fuguがその処理方法を判断します。単独モデルで十分な場合はそのまま解き、より高度な対応が求められる場合には専門モデルのチームを編成して連携させます。モデルの選択、委譲、検証、統合をすべて内部で管理するため、マルチエージェントシステムの複雑さがユーザーのコードに及ぶことは一切ありません。
これを可能にしているのは、Sakana Fugu自身が「協調の仕方」を学習しているためです。どのモデルが何を担うかを人手で定めたルールに従うのではなく、いつ委譲すべきか、エージェント同士がどう対話すべきか、そしてそれぞれの成果をどのように一つの信頼できる答えへとまとめ上げるかを、Sakana Fugu自身が学習します。このアプローチは、学習によるモデルオーケストレーションに関する私たちの最近の研究であるTrinityやConductor(いずれもICLR 2026採択論文)を基盤としています。外からは、ユーザーは単に一つのモデルを呼び出しているだけですが、内側では協調するエキスパートのシステムが働いています。
FuguとFugu Ultra
今回、Sakana Fuguとして提供を開始するのは、ワークロードに合わせて選べる2つのモデル、FuguとFugu Ultraです。いずれもOpenAI互換の単一のAPIを通じて利用できます。
Fuguは、高い性能と低レイテンシのバランスに優れ、日常的な業務のデフォルトとして最適なモデルです。コーディングやコードレビューにおけるCodexのようなツールはもちろん、チャットボットをはじめとするインタラクティブなサービスにも自然に組み込めます。データやプライバシー、コンプライアンスに関する要件を持つチーム向けには、特定のエージェントをプール(エージェント群)から除外することもできます。
Fugu Ultraは、困難な多段階の問題に対する回答品質を最大化するよう調整されており、精度と深さが最も重要な場面では、より厚みのある専門エージェント群を連携させます。テストユーザーは、データ分析、論文の再現、サイバーセキュリティ分析、文献・特許調査といった負荷の高い業務でFugu Ultraを活用していました。
FuguとFugu Ultraの標準的なベンチマークにおける性能は以下の通りです。
コーディング、リーズニング、科学、エージェント能力に関するベンチマーク群における、Fuguモデルとベースラインのフロンティアモデルの性能比較。Fugu以外のスコアは、いずれも各モデル提供元が公表した値。Fable 5とMythos Previewについては、同一ベンチマークで両方のスコアが入手できる場合、その高い方を採用した(両モデルは一般提供されていないため、Fuguのエージェントプールには含まれていない)。詳細はテクニカルレポートを参照。
Sakana Fuguと、Sakana Fuguが内部で利用する基盤モデルを比較したベンチマーク結果は以下の通りです。
*このタスクのスキャフォールディングにはmini-swe-agentを使用。
†ベースラインのスコアは各モデル提供元による公表値。
テストユーザーが見出したSakana Fuguの力
Sakana Fuguの真価は、ベンチマークの点数だけでは測りきれません。長く入り組んだ現実世界のワークフローにおいてこそ、その価値が現れるためです。そのことを確かめるため、500名近いテスターの協力を得てベータプログラムを実施し、そこで寄せられたフィードバックをもとにシステムを改善しました。
Fuguモデルの活用例。AutoResearch、ルービックキューブ、機械設計、日本語の手書き文字解析、チェス、金融時系列予測といった実験を行った。いずれの用途においても、FuguモデルはフロンティアモデルであるGemini 3.1 Pro(high)、Opus 4.8(max)、GPT 5.5(xhigh)を上回ることが示された。
ベータテストでは、あるユーザーは、Sakana Fuguのリサーチモードを用いて、データ分析をほぼ自動で進めました。データ分析は、まさにFugu Ultraが想定しているタスクそのものです。アイデアを探索し、実験を実行し、失敗を読み解き、アプローチを修正しながら、長い時間をかけて少しずつ前進し続ける、答えの定まらない多段階の作業だからです。
その他、実際に寄せられた声を紹介します。
「コードレビューでは、Fugu Ultra は回答が網羅的で、他のモデルが見逃すバグまで見つけてくれました。他のツールでは3件くらいの問題しか指摘されなかったのに対し、Sakana Fuguは20件以上を洗い出してくれました。」
— ソフトウェアエンジニア
「素の出力品質はトップクラスのフロンティアモデルと同等だと感じました。加えて Sakana Fuguは、長時間のセッションでもペルソナが安定しており、他のモデルなら崩れてしまう場面でもキャラクターを保ち続けました。エージェントにとっては、これは単純なベンチマークスコア以上に重要なことです。」
— エンタープライズ向けプラットフォーム企業の経営層
「範囲を絞った指示を一つ渡しただけで、Sakana Fuguは情報収集から XSS/SQLi の検査、認証まわりのレビュー、さらに証拠と再テスト手順を備えた整然としたレポート作成まで、セキュリティ評価を一気通貫でこなしました。しかも指定した範囲を逸脱せず、システムを壊すような操作も避けてくれました。」
— サイバーセキュリティエンジニア
論文の再現、サイバーセキュリティ分析、コードレビュー、文献・特許調査など、これらのワークフローでSakana Fuguがもたらす価値は、単一のプロンプトにより良い回答を返すことにとどまりません。読み込み、実装、テスト、証拠の比較、不足の洗い出し、そして有用な最終的な分析やレポートの作成まで、多くのステップにわたって着実に前進し続けられる点にあります。タスクが入り組んでいて長時間に及び、単一のモデル呼び出しでは解きにくいようなタスクこそ、マルチエージェントのオーケストレーションは最も効果を発揮します。
Sakana Fuguは、本日より一般提供を開始します。FuguとFugu Ultraはいずれも単一のAPIを通じて利用でき、日常利用向けのサブスクリプションプランに加え、より負荷の高い用途やエンタープライズ向けの従量課金プランをご用意しています。詳しくはプロダクトページまたはコンソールサイトをご覧ください。
おわりに:Sakana Fuguのこれから
実際の負荷の高い業務でSakana Fuguを試し、今日の姿へと磨き上げる手助けをしてくださったベータテスターの皆さまに、心より感謝申し上げます。今回のリリースは出発点であり、ゴールではありません。Sakana Fuguは固定的なワークフローではなく、学習によるオーケストレーションの上に成り立っています。そのため、基盤となるエコシステムが進歩するほど、Sakana Fugu自身も進化します。新たなフロンティアモデルが登場すれば、それをSakana Fuguのエージェント群に取り込み、その恩恵をユーザーへお渡しできます。
今後数ヶ月のうちに、専門エージェントのプールを拡充し、長時間のタスクやエージェント的なタスクにおける協調を強化し、Sakana Fuguの振る舞いをユーザーがより細かく制御できるようにしていく予定です。皆さまがSakana Fuguを使って何を生み出してくださるのか、開発者一同、心から楽しみにしています。
Sakana AIは、AIの未来を私たちと一緒に切り拓いてくださる方を募集しています。当社の募集要項をご覧ください。
関連論文
Sakana Fugu Technical Report, Fugu Team, Sakana AI, 2026.
Xu, Sun, Schwendeman, Nielsen, Cetin, Tang. TRINITY: An Evolved LLM Coordinator. ICLR 2026.
https://arxiv.org/abs/2512.04695
Nielsen, Cetin, Schwendeman, Sun, Xu, Tang. Learning to Orchestrate Agents in Natural Language with the Conductor. ICLR 2026.
https://arxiv.org/abs/2512.04388